 Dokumentation
Dokumentation Anmeldung
AnmeldungLinux Kernel CVE-Datenanalyse (aktualisiert)

13. Dezember 2021. TuxCare PR Team
Wenn Sie sich für Linux-Sicherheit und Kernel-Schwachstellen interessieren oder einfach nur etwas Zeit haben, um einige Tests durchzuführen, ist dieser Artikel genau das Richtige für Sie. Darin stellen wir eine aktualisierte Version einer Methode zur Verfügung, mit der Sie Daten aus CVE-Repositories extrahieren und Ihre eigene statistische Analyse erstellen können. Finden Sie heraus, welche Kernel-Versionen die meisten identifizierten Sicherheitslücken aufweisen.
|
Anmerkung des Herausgebers: Dieser Artikel ist eine aktualisierte Version einer Reihe von Artikeln, die im alten KernelCare-Blog veröffentlicht wurden. In der Zeit seit ihrer Veröffentlichung hat sich das Datenformat in den CVE-Repositories geändert, so dass die ursprünglichen Anweisungen nicht mehr funktionierten. Anstatt alte Artikel zu aktualisieren, die keine Sichtbarkeit erhalten würden, veröffentlichen wir den gesamten Inhalt mit funktionierenden Schritt-für-Schritt-Anleitungen neu. Wir sind uns darüber im Klaren, dass die Ergebnisse etwas verzerrt sind, da einige Kernel-Versionen weiter verbreitet sind als andere und daher ausgiebiger getestet werden, und CVEs nicht der beste Weg sind, um das (Un-)Sicherheitsniveau einer bestimmten Kernel-Version zu bestimmen. Dennoch ist es eine interessante Übung, die Ihnen die Möglichkeit gibt, mehrere Tools zu nutzen, die Sie sonst vielleicht nie verwenden würden. Sie haben jetzt eine Möglichkeit, Behauptungen über "so viele Sicherheitslücken für diesen oder jenen Kernel" selbst zu überprüfen, und mit dieser grundlegenden Arbeit könnten Sie, mit einigen Änderungen, die Sicherheitslücken anderer Projekte statt nur des Kernels verfolgen. Ein "Dankeschön" an Paul Jacobs, der die aktualisierte Fassung seiner ursprünglichen Artikel eingereicht hat. |
Inhalt
Teil 1 - Einrichtung und Datenerfassung
Teil 3 - Erweiterte Abfragen und Diagramme
Aktualisiert für 2021. Änderungen:
-
- Mango Abfrage-Selektor-Syntax für CVE 1.1-Spezifikation aktualisiert.
- Verwendet CouchDB Docker Container.
Teil 1
Die Entwickler des Linux-Kernels sagen uns, dass der "beste" Linux-Kernel derjenige ist, der in der von uns verwendeten Distribution enthalten ist. Oder die letzte stabile Version. Oder die neueste Version mit Langzeitunterstützung (LTS). Oder was immer wir wollen, solange es gewartet wird.
Die Auswahl ist großartig, aber ich hätte lieber eine einzige Antwort; ich will einfach das Beste. Das Problem ist, dass für manche Menschen das Beste gleichbedeutend ist mit dem Schnellsten. Für andere ist der Beste derjenige mit den neuesten Funktionen oder einer bestimmten Funktion. Für mich ist der beste Linux-Kernel der sicherste.
Welcher ist der "sicherste" Linux-Kernel?
Eine grobe Möglichkeit, die Sicherheit einer Software zu beurteilen, besteht darin, zu sehen, wie viele Sicherheitslücken in einer bestimmten Version der Software auftreten. (Ich weiß, dass dies eine wackelige Prämisse ist, aber lassen Sie es uns trotzdem versuchen, und sei es nur, um mehr über CVEs und deren Interpretation zu lernen.) Wendet man diese Taktik auf den Linux-Kernel an, so bedeutet dies, dass man die Berichte über Sicherheitslücken untersucht.
Das ist es, was ich in dieser Serie von drei Artikeln tun werde. Ich werde die CVEs (gemeldete Sicherheitslücken) des Linux-Kernels analysieren, um zu sehen, ob es irgendwelche Trends gibt, die bei der Beantwortung der Frage helfen können, welcher der beste (d.h. sicherste) Linux-Kernel zu verwenden ist.
Aber Moment - wurde das nicht schon einmal gemacht?
Irgendwie schon.
-
CVE-Details: Eine CVE-Suchmaschine. Sie können CVEs nach Schweregrad, Produkt, Anbieter usw. finden.
-
Linux-Kernel CVEs: Auch eine CVE-Suchmaschine, die CVE-IDs für bestimmte Linux-Kernel-Versionen auflistet.
-
Alexander Leonov: Schöner Artikel über die Anatomie einer CVE-Datendatei, aber mit einem Schwerpunkt auf CPE-Daten.
-
Tenable.sc: Kommerzielles Produkt mit einem CVE-Analyse-Dashboard.
Warum also dies tun?
Denn entweder beantworten diese Ressourcen und Projekte meine Frage nicht, oder sie kosten Geld.
Außerdem möchte ich lernen, was eine CVE ist, was sie mir über die Unterschiede (falls vorhanden) zwischen Linux-Kernel-Versionen sagen können und wo die Grenzen dieses Ansatzes liegen.
Das Verfahren und die Instrumente
Es ist ganz einfach: Daten sammeln, analysieren und die Ergebnisse grafisch darstellen.
Die Tools sind kostenlos und laufen auf vielen Plattformen. Ich werde mit Debian Linux arbeiten und gehe davon aus, dass Sie sich vom Anblick eines nackten Terminals nicht abschrecken lassen.
Damit Sie wissen, worauf Sie sich einlassen, hier die wichtigsten Schritte.
-
Verwenden Sie Docker, um die neueste Version von Apache CouchDB auszuführen. (Dies wird ein Single-Node-Setup sein - ich möchte die Daten erforschen und mich nicht mit der Administration aufhalten).
-
Laden Sie NVD-Daten (als JSON-Dateien) herunter und importieren Sie alle CVE-Datensätze, nicht nur die für den Linux-Kernel. (Auf diese Weise ist es einfacher, relevante Daten zur Abfragezeit auszuwählen, als Datensätze aus den JSON-Dateien zu analysieren und zu extrahieren).
-
Verwenden Sie Mango zur Abfrage der Daten.
Zunächst ein paar Hintergrundinformationen darüber, was ein CVE ist und was ein CVE-Datensatz enthält.
Was ist ein CVE?
CVE steht für Common Vulnerability and Exposures (Gemeinsame Schwachstellen und Gefährdungen).
Für unsere Zwecke ist ein CVE ein Code, der eine Software-Schwachstelle identifiziert. Er hat die Form CVE-YYYY-Nwobei YYYY das Jahr ist, in dem die ID zugewiesen oder veröffentlicht wurde, und N eine Sequenznummer von beliebiger Länge ist. Eine Organisation namens Gehrung koordiniert die CVE-Liste.
Ein CVE wird natürlich nicht durch seine ID definiert, sondern durch seine Details. Eine Reihe von Organisationen kümmert sich um diese Details, aber die, die ich verwenden werde, ist die bekannteste: die National Vulnerability Database (NVD), die vom National Institute of Standards and Technology (NIST) verwaltet wird. Jeder kann ihre CVE-Daten kostenlos herunterladen.
Das NIST hat einige einfache Balkendiagramme, die zeigen, wie der Schweregrad von Sicherheitslücken je nach Jahr variiert. Es handelt sich dabei um Diagramme für alle Software CVEs (nicht nur für Linux), von 2001 bis zum aktuellen Jahr. Ich möchte etwas Ähnliches, aber nur für Linux-Schwachstellen, und auch aufgeschlüsselt nach Kernel-Version.
Was ist in einem CVE enthalten?
Bevor ich die Schwachstellendateien im JSON-Format lade und abfrage, möchte ich Ihnen zeigen, was in ihnen enthalten ist. (Es gibt ein Dateispezifikationsschema, aber es enthält viele Details, die wir nicht kennen müssen). Jede NVD CVE-Datei enthält die CVEs eines Jahres (1. Januar bis 31. Dezember). Hier ist die Grundstruktur eines CVE-Eintrags.
-
Der erste JSON-Abschnitt ist ein Header, der das Datenformat, die Version, die Anzahl der Datensätze und einen Zeitstempel enthält.
-
Der Rest ist ein großes Feld,
CVE_Itemsmit diesen Unterelementen:cveproblemtypereferencesdescriptionconfigurationsimpact- und zwei Datumsfelder,
publishedDateundlastModifiedDate.
Von Interesse ist die
configurations. Es enthält:nodes, eine Reihe von:children, eine Reihe von:cpe_match, bestehend aus:vulnerablecpe23Uri: A Gemeinsame Plattformaufzählung String.cpe_name
Es ist die
cpe23UriundimpactTeile, die ich letztendlich abfragen werde.-
Der Auswirkungsblock definiert den Schweregrad einer Sicherheitslücke als Zahl und Bezeichnung unter Verwendung des Common Vulnerability Scoring System (CVSS). (Es gibt zwei Versionen, 2.0 und 3.0, die sich wie unten dargestellt leicht unterscheiden).
-
Die Zahl ist die Basispunktebereich (
baseScore), ein Dezimalwert von 0,0 bis 10,0. -
Der Name (
severity) ist einer der Werte LOW, MEDIUM oder HIGH (für CVSS V2.0; NONE und CRITICAL werden in v3.0 hinzugefügt).
-
CVSS v2.0 gegenüber v3.0
Die beiden Versionen unterscheiden sich darin, wie sie die Basisbewertung dem Schweregrad zuordnen. (Die folgende Tabelle stammt von der NVD-CVSS-Seite.)
| CVSS v2.0 Bewertungen | CVSS v3.0 Bewertungen | ||
|---|---|---|---|
| Schweregrad | Basispunktebereich | Schweregrad | Basispunktebereich |
| Keine | 0.0 | ||
| Niedrig | 0.0-3.9 | Niedrig | 0.1-3.9 |
| Mittel | 4.0-6.9 | Mittel | 4.0-6.9 |
| Hoch | 7.0-10.0 | Hoch | 7.0-8.9 |
| Kritisch | 9.0-10.0 | ||
Jetzt richte ich CouchDB ein, lade die Daten und frage sie mit Mango ab.
CouchDB über Docker ausführen
-
Holen Sie sich Docker für Ihre Plattform.
-
Kopieren Sie diese Befehle, fügen Sie sie in ein Terminal ein und führen Sie sie aus. (Von nun an gehe ich davon aus, dass Sie einen Befehl erkennen, wenn Sie ihn sehen, und wissen, was Sie damit tun müssen).
sudo docker run -d
-p 5984:5984
-e COUCHDB_USER=admin
-e COUCHDB_PASSWORT=Passwort
-name couchdb couchdb- Ich benutze
passwordhier. Wählen Sie Ihre eigene, aber achten Sie darauf, wo sie von nun an verwendet wird. - Wenn Sie es vorziehen, CouchDB nativ zu installieren (als reguläre Anwendungsinstallation, anstatt in einem Container), lesen Sie docs.couchdb.org.
- Ich benutze
-
Öffnen Sie einen Webbrowser und rufen Sie http://localhost:5984/_utils auf.
-
Melden Sie sich mit den im Docker-Befehl verwendeten Anmeldedaten an (die Werte für
COUCHDB_USERundCOUCHDB_PASSWORD). -
Wählen Sie im Fensterbereich Datenbanken die Option Datenbank erstellen.
-
Unter Name der Datenbankeingeben
nvd(oder ein von Ihnen gewählter Name für die Datenbank). -
Wählen Sie für Partitionierung die Option Nicht partitioniert.
- Klicken Sie auf Erstellen.
CVE-Daten in CouchDB importieren
- Prüfen Sie, ob curl und jq auf Ihrem System vorhanden sind (oder installieren Sie sie, falls nicht).
| curl -Version || sudo apt install -y curl jq -Version || sudo apt install -y jq |
- Installieren Sie Node.js und das Couchimport-Tool.
| sudo apt-get install -y npm npm install -g couchimport |
- Laden Sie CVE JSON-Datendateien herunter.
| VERS=“1.1” R=“https://nvd.nist.gov/feeds/json/cve/${VERS}/” for YEAR in $(seq 2009 $(date +%Y)) do FILE=$(printf “nvdcve-${VERS}-%s.json.gz” $YEAR) URL=“${R}${FILE}“ echo “Downloading ${URL} to ${FILE}“ curl ${URL} –output ${FILE} –progress-bar –retry 10 done |
-
- Passen Sie den Jahresbereich Ihren Interessen an. NVD hat Daten ab 2002.
- Die Version ändert sich von Zeit zu Zeit. Prüfen Sie https://nvd.nist.gov/vuln/data-feeds und stellen Sie VERS entsprechend ein, achten Sie aber auch auf Änderungen des Dateiformats.
- Dekomprimieren Sie die Dateien.
| gunzip *.gz |
- Importieren Sie CVE-Daten in die CouchDB-Datenbank.
| export COUCH_URL=“http://admin:password@localhost:5984” COUCH_DATABASE=“nvd” COUCH_FILETYPE=“json” COUCH_BUFFER_SIZE=100 for f in $(ls -1 nvdcve*.json); do echo “Importing ${f}“ cat ${f} | couchimport –jsonpath “CVE_Items.*” done |
-
- Ändern Sie COUCH_DATABASE, wenn Sie sie mit einem anderen Namen erstellt haben.
- Verwenden Sie die Option -preview true, um einen Trockenlauf durchzuführen.
- Wenn einer davon fehlschlägt, verringern Sie die Größe von COUCH_BUFFER_SIZE. Der Standardwert ist 500, aber (bei mir) schlägt das Importieren der Daten von 2020 fehl, wenn die Puffergröße nicht verringert wird.
- Lesen Sie mehr über couchimport.
- Überprüfen Sie, ob die Anzahl der Datensätze in der Datenbank und in den Dateien übereinstimmt. (Die Zählungen dieser beiden Befehle sollten übereinstimmen.)
| grep CVE_data_numberOfCVEs nvdcve*.json | cut -d‘:’ -f3 | tr –cd ‘[:digit:][:cntrl:]’ | awk ‘{s+=$1} END {print s}’ |
| curl -sX GET ${COUCH_URL}/nvd | jq '.doc_count' |
-
- Wenn die Zählungen voneinander abweichen, überprüfen Sie die Ausgabe des vorherigen Schritts und suchen Sie nach Importfehlern.
Eine Mango-Abfrage in Fauxton ausführen
Um diese erste Abfrage zu vereinfachen, werde ich Fauxton, die browserbasierte CouchDB-Benutzeroberfläche, verwenden. Aber machen Sie sich nicht zu sehr damit vertraut, denn in den Teilen 2 und 3 werde ich ausschließlich über die Kommandozeile arbeiten.
- Gehen Sie in einem Browser auf: http://localhost:5984/_utils/#database/nvd/_find
Fauxton wird Sie nach einer gewissen Zeit der Inaktivität abmelden. Wenn das passiert, loggen Sie sich aus und wieder ein, navigieren Sie zu Datenbanken, wählen Sie die nvd-Datenbank aus (wenn das der Name ist, den Sie verwendet haben) und führen Sie eine Abfrage mit Mango durch. - Löschen Sie den Inhalt des Mango-Abfragefensters, kopieren Sie dann diesen Abfragetext und fügen Sie ihn dort ein:
| { “selector”: { “configurations.nodes”: { “$elemMatch”: { “operator”: “OR”, “cpe_match”: { “$elemMatch”: { “cpe23Uri”: { “$regex”: “linux_kernel” } } } } }, “publishedDate”: { “$gte”: “2021-01-01”, “$lte”: “2021-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } |
- Stellen Sie Dokumente pro Seite auf den höchsten Wert ein.
- Klicken Sie auf Abfrage ausführen.
Das Ergebnis ist eine Liste der CVE-IDs von Linux-Kernel-Schwachstellen für alle Schweregrade und Kernel-Versionen, die im Jahr 2021 zugewiesen oder veröffentlicht wurden.
Hausaufgaben
- Kopieren Sie die cve.CVE_data_meta.ID und fügen Sie sie in die NVD-Suchseite ein, um die Details einer beliebigen CVE anzuzeigen.
- Experimentieren Sie mit verschiedenen Datumsbereichen. Um zum Beispiel mit Januar 2019 zu beginnen, ersetzen Sie das Element publishedDate durch:
“publishedDate”: {
“$gte“: “2019-01-01”,
“$lte“: “2019-12-31”
}
Herzlichen Glückwunsch! Sie sind nun stolzer Besitzer einer CouchDB-Datenbank, die über ein Jahrzehnt (oder was immer Sie gewählt haben) an CVEs enthält. Denken Sie daran, dass die Datenbank Daten für alle Software von allen Anbietern enthält.
Als Nächstes füge ich Selektoren für Schweregrad und Kernelversion hinzu, führe die Abfragen aus und stelle die Ergebnisse grafisch dar.
Teil 2
Vorbereitende Maßnahmen
Legen Sie einige Verzeichnisse an, um den Überblick zu behalten.
| mkdir bin qry img out |
- Ich werde sie so verwenden:
- bin: Skripte;
- qry: Mango-Abfrage-Dateien;
- img: Bilder von Diagrammen;
- out: Ausgabe der Abfragen.
Installieren Sie Gnuplot.
| sudo apt install -y gnuplot |
Als Nächstes werde ich mir ansehen, wie die Anzahl der Sicherheitslücken im Linux-Kernel von Jahr zu Jahr variiert. Dazu füge ich Parameter mit printf-Tokens in die Mango-Abfragen ein, wobei die Werte zur Laufzeit ersetzt werden. (Später werde ich auch Parameter für die Kernel Version hinzufügen.) Um die Dinge schnell und einfach zu halten, werde ich das CouchDB POST API verwenden, um Abfragen auf der Kommandozeile zu übermitteln.
Abfrage 1a - CVEs im Linux-Kernel nach Jahr
Führen Sie dies aus, um eine Mango-Abfragedatei zu erstellen:
| cat<<EOF>qry/1-linux-kernel-cves-by-year.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Führen Sie das aus.
| für JAHR in $(seq 2009 $(Datum +%Y)); do echo -de "$JAHRt" printf "$(cat qry/1-linux-kernel-cves-by-year.json)" JAHR $JAHR | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find -header "Content-Type:application/json" | jq '.docs | length' done | tee out/1-linux-kernel-cves-by-year.tsv |
-
- Dies führt die Abfrage in einer Schleife für jedes Jahr im Bereich (Zeile 1) aus und gibt die Ergebnisse sowohl auf der Konsole als auch in out/1-linux-kernel-cves-by-year.tsv aus (die ich für die grafische Darstellung verwenden werde).
- Ändern Sie die Jahresspanne nach Ihren Interessen oder nach dem, was Sie in Teil 1 importiert haben.
- Wenn Sie keine Ergebnisse erhalten, überprüfen Sie die Abfragedatei(qry/1-linux-kernel-cves-by-year.json) und Ihre CouchDB Anmeldedaten (admin/password).
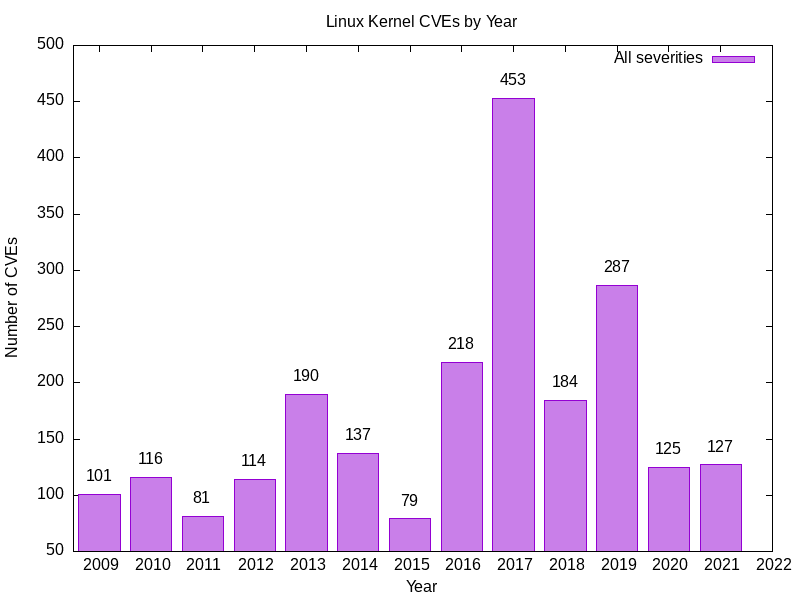
Hier ist die Ausgabe, die ich erhalte.
2009 101
2010 116
2011 81
2012 114
2013 190
2014 137
2015 79
2016 218
2017 453
2018 184
2019 287
2020 125
2021 127
- Dies ist die Anzahl der Sicherheitslücken im Linux-Kernel für jedes Jahr.
- Einige Ihrer Zahlen könnten höher sein, da Schwachstellen auch im Nachhinein erfasst werden können.
Führen Sie dies aus, um ein Gnuplot-Skript in bin/1-linux-kernel-cves-by-year.gnuplot zu erstellen:
| cat<<EOF>bin/1-linux-kernel-cves-by-year.gnuplot reset set terminal png size 800,600 set output ‘img/1-linux-kernel-cves-by-year.png’ set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right set title ‘Linux Kernel CVEs by Year’ set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [2008.5:*] [] ‘out/1-linux-kernel-cves-by-year.tsv’ w boxes t ‘All severities’, ‘out/1-linux-kernel-cves-by-year.tsv’ u 1:($2+15):2 w labels t ” EOF |
- Führen Sie dies aus, um eine Bilddatei in img/1-linux-kernel-cves-by-year.png zu erstellen:
| gnuplot -c bin/1-linux-kernel-cves-by-year.gnuplot |
- Öffnen Sie img/1-linux-kernel-cves-by-year.png in Ihrem bevorzugten Bildbetrachter. Hier ist meins.
Kommentar
Das sind eine Menge Sicherheitslücken im Linux-Kernel. 2017 war ein spektakulär gutes/schlechtes Jahr für Sicherheitslücken im Linux-Kernel.
Ich war beunruhigt, als ich dies sah, also habe ich andere Quellen, darunter CVEDetails, abgeglichen. Die Zahlen stimmen ziemlich gut überein.
Jahr Bergwerk CVDetails
2009 101 104
2010 116 118
2011 81 81
2012 114 114
2013 190 186
2014 137 128
2015 79 79
2016 218 215
2017 453 449
2018 184 178
2019 287 289
2020 125 126
2021 127 130
Etwaige Unterschiede lassen sich durch die Beobachtungen von CVE Details erklären:
"... CVE-Daten weisen Inkonsistenzen auf, die sich auf die Genauigkeit der angezeigten Daten auswirken ... So können beispielsweise Schwachstellen im Zusammenhang mit Oracle Database 10g für die Produkte 'Oracle Database', 'Oracle Database10g', 'Database10g', 'Oracle 10g' und ähnliche definiert worden sein."
Mit anderen Worten: Die CVE-Daten des NVD sind nicht ganz genau. (Mehr dazu später.)
Dieses Diagramm zeigt die Gesamtzahl der CVEs, die über alle CVE-Schweregrade aggregiert sind. Um die Ergebnisse nach Schweregrad aufzuschlüsseln, werde ich der Mango-Abfrage einen Selektor hinzufügen.
Abfrage 1b - CVEs im Linux-Kernel nach Jahr und Schweregrad
- Führen Sie dies aus, um qry/cve-1b.json zu erstellen (eine Kopie der Abfrage 1a mit einem zusätzlichen Schweregradparameter):
| cat<<EOF>qry/2-linux-kernel-cves-by-year-and-severity.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “impact.baseMetricV2.severity”: “%s”, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Führen Sie das aus.
| export OUT=“2-linux-kernel-cves-by-year-and-severity” SEVS=(LOW MEDIUM HIGH) (IFS=$‘t’; echo -e “YEARt${SEVS[*]}“ | tee out/${OUT}.tsv); for YEAR in $(seq 2009 $(date +%Y)); do RES=() echo -en “$YEARt” for SEV in ${SEVS[*]}; do RES+=($(printf “$(cat qry/${OUT}.json)“ ${SEV} ${YEAR} ${YEAR} | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
Hier ist mein Ergebnis.
YEAR LOW MEDIUM HIGH
2009 11 51 39
2010 37 47 32
2011 19 41 21
2012 24 66 24
2013 46 126 18
2014 20 87 30
2015 17 44 18
2016 25 114 79
2017 73 91 289
2018 36 93 55
2019 47 151 89
2020 38 64 23
2021 44 59 24
- Führen Sie dies aus, um ein Gnuplot-Skript in bin/cve-1b.gnuplot zu erstellen:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set style data histograms set style histogram rowstacked set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right title “Severity” set title “Linux kernel CVEs” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot “out/`echo ${OUT}`.tsv” u ($2):xtic(1) t col, ” u ($3):xtic(1) t col, ” u ($4):xtic(1) t col, ” u ($0-1):($2+10):(sprintf(“%d”,$2)) with labels t ”, ” u ($0-1):($2+$3+10):(sprintf(“%d”,$3)) with labels t ”, ” u ($0-1):($2+$3+$4+10):(sprintf(“%d”,$4)) with labels t ” EOF |
- Führen Sie dies aus, um eine Bilddatei in img/cve-1b.png zu erstellen.
| gnuplot -c bin/${OUT}.gnuplot |
Hier ist meine.
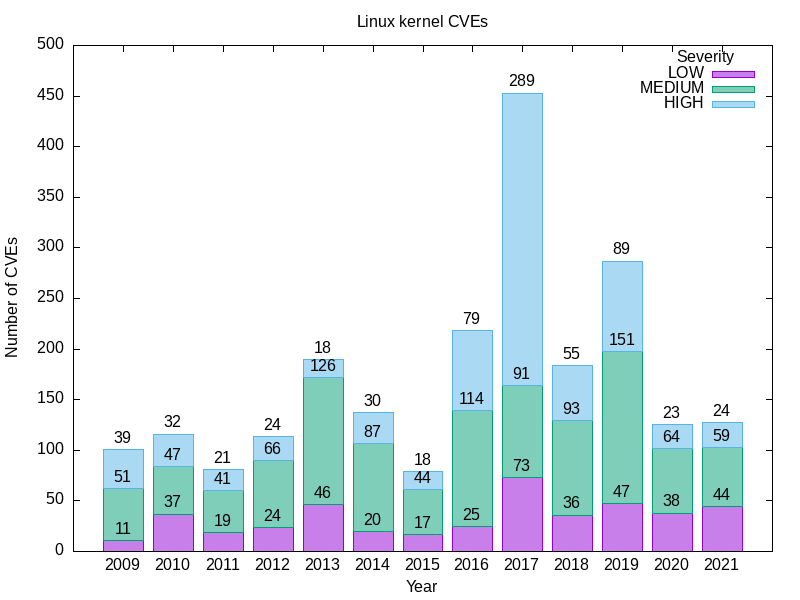
Hinweise zum Schweregrad
-
- Die Abfrage 1b verwendet CVSS Version 2 und nicht die neuere Version 3. Dafür gibt es einen Grund. CVSS Version 3 wurde im Dezember 2015 eingeführt; CVEs vor diesem Datum können nur mit dem CVSS-Schema der Version 2 ausgewählt werden.
- In den CVSS-Versionen 2 und 3 gibt es sowohl numerische als auch textuelle Darstellungen für den Schweregrad. Die numerische Darstellung ist präziser, während die textuelle Darstellung gröber, aber einfacher zuzuordnen ist. Der Einfachheit halber verwende ich hier das textuelle Schema. Aus Gründen der Genauigkeit werde ich später auf das numerische Schema umsteigen.
Abfrage 1b ergibt ein schärferes Bild als Abfrage 1a, aber nicht weniger schockierend. Vergleichen Sie zum Beispiel den relativen Anteil von Sicherheitslücken mit hohem Schweregrad im Linux-Kernel mit denen vor und nach 2016.
Es könnte sein, dass viele dieser Schwachstellen in einigen wenigen Kernel-Versionen konzentriert sind. Ich werde es erst wissen, wenn ich die Abfrage so modifiziert habe, dass sie sowohl nach Version als auch nach Jahr und Schweregrad selektiert. Das kommt als nächstes.
Teil 3
In Teil 3 entwickle ich diese zentrale Mango-Abfrage weiter, um zu untersuchen, wie die Anzahl der Sicherheitslücken im Linux-Kernel je nach Kernel-Version variiert.
Da es so viele Versionen gibt, werden die Abfragen und Befehle immer komplizierter und dauern länger. Daher werde ich vorerst nur das Jahr und die Kernel-Version variieren. Der Schweregrad bleibt ein Parameter, aber ich werde die Ergebnisse für alle Schweregrade abfragen.
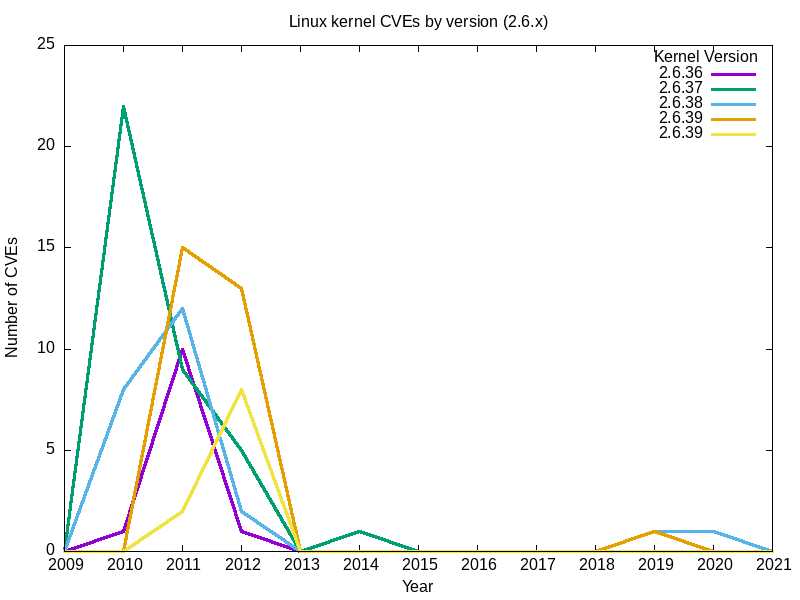
Ich beginne mit einem Blick auf die letzten fünf Versionen (2.6.35 bis 2.6.39) des berühmt-berüchtigten 2.6.x Linux-Kernel-Zweigs.
Abfrage 2 - CVEs im Linux-Kernel nach Jahr und Kernel-Version
- Führen Sie dies aus, um eine Abfragedatei zu erstellen:
| export QRY=“3-linux-kernel-cves-by-year-and-version” cat<<EOF>qry/${QRY}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Führen Sie das aus.
| export VERS_MAJOR=2.6 VERS_MINOR_START=35 VERS_MINOR_STOP=39 YEAR_START=2009 YEAR_STOP=$(date +%Y) VERSIONS=() COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” export OUT=“${QRY}_${VERS_MAJOR}.x” for VERS_MINOR in $(seq ${VERS_MINOR_START} ${VERS_MINOR_STOP}); do VERSIONS+=(${VERS_MAJOR}.${VERS_MINOR}); done (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
- Das Ergebnis:
| 2.6.35 2.6.36 2.6.37 2.6.38 2.6.39 2009 0 0 0 0 0 2010 1 22 8 0 0 2011 10 9 12 15 2 2012 1 5 2 13 8 2013 0 0 0 0 0 2014 1 1 0 0 0 2015 0 0 0 0 0 2016 0 0 0 0 0 2017 0 0 0 0 0 2018 0 0 0 0 0 2019 0 0 1 1 0 2020 0 0 1 0 0 2021 0 0 0 0 0 |
- Führen Sie dies aus, um das Gnuplot-Skript zu erstellen:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version (`echo ${VERS_MAJOR}`.x)” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/`echo ${OUT}`.tsv” using 1:c with lines lw 3 EOF |
- Führen Sie gnuplot aus, um die Bilddatei zu erstellen.
| gnuplot -c bin/${OUT}.gnuplot |
- Hier ist meine.
Skript für Linux-Kernel 3.x, 4.x, 5.x CVEs nach Jahr und Version
Hier ist ein Skript, das die letzten drei Befehle in einem einzigen Block kombiniert und Umgebungsvariablen verwendet, um die letzten fünf Versionen der anderen großen Linux-Kernel-Zweige abzufragen.
Speichern Sie den Code in einer Datei, machen Sie ihn ausführbar und führen Sie ihn aus. Und warten.
| #!/bin/bash # Script to chart Linux kernel CVEs for kernel versions # 3.x, 4.x, 5.x. # You must have loaded a CouchDB database with CVE # data as described here: # https://blog.kernelcare.com/linux-kernel-cve-data-analysis-part-1-importing-into-couchdb # Parallel arrays for Linux kernel versions: # 3.0-3.19 (2011-DATE) # 4.0-4.20 (2015-DATE) # 5.0-5.12 (2019-DATE) VERS_MAJOR=(3 4 5) VERS_MINOR_START=(0 0 0) VERS_MINOR_STOP=(19 20 12) YEAR_START=(2011 2015 2019) YEAR_STOP=$(date +%Y) # admin/password are CouchDB admin login credentials COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” ## # Construct version string from args # and set VERSIONS. # Args: # 1: Major version number # 2: Minor version start number # 3: Minor version stop number build_versions() { VERSIONS=() for VERS_MINOR in $(seq ${2} ${3}); do VERSIONS+=(${1}.${VERS_MINOR}) done } ## # Write a query file to qry subdir # Args: # 1: Name of query file without extension write_query() { cat<<EOF>qry/${1}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF } ## # Run the query # run_query() { (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START[$i]} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv } # Run a gnuplot script with values supplied # by: # 1: Base of filename # 2: Major version number # 3: As per 1 run_gnuplot() { printf ‘ reset set terminal png size 800,600 set output “img/%s.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version %s.x” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/%s.tsv” using 1:c with lines lw 3 ‘ $1 $2 $1 | gnuplot – } main() { write_query ${QRY} for i in 0 1 2; do build_versions ${VERS_MAJOR[$i]} ${VERS_MINOR_START[$i]} ${VERS_MINOR_STOP[$i]} OUT=“${QRY}_${VERS_MAJOR[$i]}.x” run_query run_gnuplot $OUT ${VERS_MAJOR[$i]} done } main |
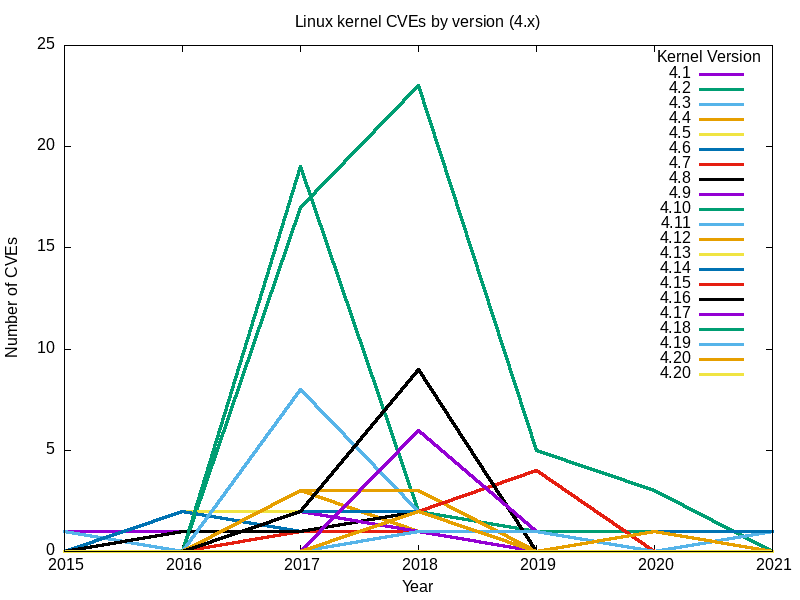
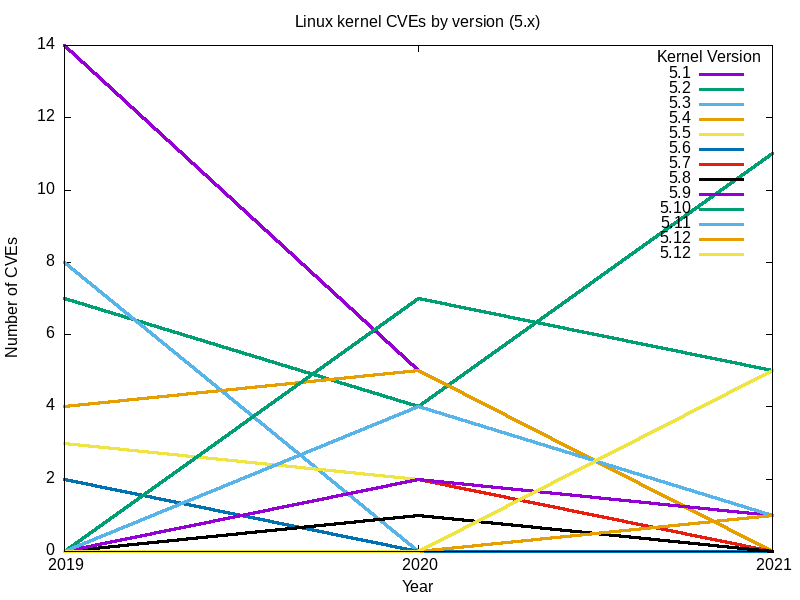
Hier sind die resultierenden Diagramme.
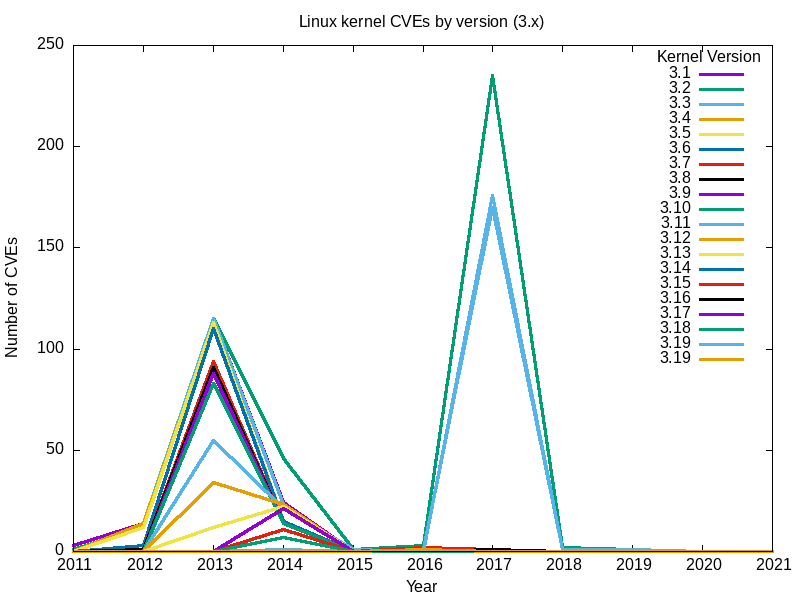
Ja, der große Anstieg im Jahr 2017 war hauptsächlich auf die in Version 3.18 gefundenen Sicherheitslücken zurückzuführen.
Schlussfolgerungen
-
Zusammengenommen scheint der vollständige Satz von Diagrammen für alle wichtigen Linux-Kernel-Zweige meine ursprüngliche Frage zu beantworten: Der sicherste Linux-Kernel (der mit den wenigsten Sicherheitslücken) ist die neueste[Anmerkung des Herausgebers: zum Zeitpunkt der Erstellung dieses Artikels], Version 5.12.
-
Die Auswirkungen vieler Schwachstellen gehen über die Zweige und das End-of-Life-Datum hinaus. Die letzte Version von 2.6, 2.6.39, wurde zum Beispiel im Mai 2011 veröffentlicht. Im August desselben Jahres wurde die Version 2.6.39.4 als "End of Life" bezeichnet. Dennoch haben die Berichte über Sicherheitslücken nicht aufgehört, sondern seit 2016 sogar zugenommen.
-
Der Vergleich von Schwachstellen nach Zweigen ist nicht der beste Weg. Zweige sind fortlaufend, wobei die letzte Version eines Zweiges die Grundlage für den nächsten bildet. Zum Beispiel ist 5.0 eine Fortsetzung des 4.x-Zweigs, 4.0 eine Fortsetzung von 3.19 und die letzte Version 2.6.39 des langjährigen 2.6-Zweigs wurde in 3.0 fortgesetzt. Die Art und Weise, wie Codebasen auf diese Weise verzweigt werden, bedeutet, dass jeder nachfolgende Zweig immer weniger Fehler aufweist.


