 Documentación
Documentación Inicio de sesión
Inicio de sesiónAnálisis de datos de CVE del núcleo de Linux (actualizado)

13 de diciembre de 2021 - Equipo de RRPP de TuxCare
Si te interesa la seguridad en Linux, las vulnerabilidades del kernel o simplemente tienes algo de tiempo libre para hacer algunas pruebas, este artículo es para ti. En él, ofrecemos una versión actualizada de una metodología que puedes utilizar para extraer datos de los repositorios de CVE y crear tus propios análisis estadísticos. Averigua qué versiones del kernel tienen más vulnerabilidades identificadas.
|
Nota del editor: Este artículo es una versión actualizada de una serie de artículos publicados en el antiguo blog KernelCare. En el tiempo transcurrido desde su publicación, el formato de los datos en los repositorios de CVE cambió, por lo que las instrucciones originales dejaron de funcionar. En lugar de actualizar artículos antiguos que no tendrían visibilidad, volvemos a publicar todo el contenido con instrucciones paso a paso que funcionan. Somos conscientes de que los resultados están algo sesgados debido a que algunas versiones del kernel tienen una adopción más extendida que otras y, por tanto, se prueban de forma más exhaustiva, y a que los CVE no son la mejor forma de afirmar el nivel de (in)seguridad de una versión determinada del kernel. Sin embargo, sigue siendo un ejercicio interesante y, aunque sólo sea por eso, te permitirá poner en práctica múltiples herramientas que de otro modo nunca utilizarías. Ahora tienes una forma de comprobar por ti mismo las afirmaciones de "tantas vulnerabilidades para tal o cual kernel", y con este trabajo de base podrías, con algunos cambios, rastrear las vulnerabilidades de otros proyectos en lugar de sólo del kernel. Un "gracias" a Paul Jacobs, que envió la versión actualizada de sus artículos originales. |
Contenido
Parte 1 - Configuración y adquisición de datos
Parte 3 - Consultas y gráficos avanzados
Actualizado para 2021. Cambios:
-
- Sintaxis del selector de consultas de Mango actualizada para la especificación CVE 1.1.
- Utiliza el contenedor Docker CouchDB.
Parte 1
Los desarrolladores del kernel de Linux nos dicen que el "mejor" kernel de Linux que podemos utilizar es el que viene con la distribución que estemos usando. O la última versión estable. O la versión de soporte a largo plazo (LTS) más reciente. O la que queramos, siempre que se mantenga.
Elegir está muy bien, pero yo prefiero tener una sola respuesta; sólo quiero lo mejor. El problema es que, para algunas personas, mejor significa más rápido. Para otros, el mejor es el que tiene las últimas características, o una característica específica. Para mí, el mejor núcleo Linux es el más seguro.
¿Cuál es el núcleo Linux "más seguro"?
Una forma burda de considerar la seguridad de un software es ver cuántos problemas de seguridad aparecen en una versión específica del mismo. (Sé que es una premisa poco sólida, pero vamos a seguir con ella, aunque sólo sea como forma de aprender más sobre los CVE y cómo interpretarlos). Aplicar esta táctica al núcleo Linux significa examinar los informes de vulnerabilidades.
Eso es lo que haré en esta serie de tres artículos. Analizaré los CVE (vulnerabilidades notificadas) del kernel de Linux para ver si hay alguna tendencia que pueda ayudar a responder a la pregunta: ¿Cuál es el mejor kernel de Linux (es decir, el más seguro) que se puede utilizar?
Pero espere, ¿no se ha hecho ya?
Algo así.
-
Detalles de CVE: Un motor de búsqueda de CVE. Puede encontrar CVE por gravedad, producto, proveedor, etc.
-
CVEs del núcleo Linux: También un motor de búsqueda de CVE, que enumera los ID de CVE para versiones específicas del núcleo de Linux.
-
Alexander Leonov: Buen artículo sobre la anatomía de un archivo de datos CVE, pero centrado en los datos CPE.
-
Tenable.sc: Producto comercial con un panel de análisis de CVE.
Entonces, ¿por qué hacer esto?
Porque, o bien esos recursos y proyectos no responden a mi pregunta, o bien cuestan dinero.
Y además, quiero aprender qué es un CVE, qué me pueden decir sobre las diferencias (si las hay) entre las versiones del kernel de Linux y cuáles son las limitaciones de este enfoque.
El proceso y las herramientas
Es muy sencillo: obtener los datos, analizarlos y trazar los resultados.
Las herramientas son gratuitas y funcionan en muchas plataformas. Yo trabajaré en Debian Linux, y asumiré que no te asusta ver un terminal desnudo.
Para que sepas lo que te espera, aquí tienes los pasos clave.
-
Utiliza Docker para ejecutar la última versión de Apache CouchDB. (Esta será una configuración de un solo nodo: quiero explorar los datos, no atascarme con la administración).
-
Descargue los datos NVD (como archivos JSON) e importe todos los registros CVE, no sólo los del núcleo Linux. (De esta forma es más fácil seleccionar los datos relevantes en el momento de la consulta que analizar y extraer los registros de los archivos JSON).
-
Utiliza Mango para consultar los datos.
En primer lugar, explicaremos qué es un CVE y qué contiene un registro CVE.
¿Qué es un CVE?
CVE son las siglas en inglés de Vulnerabilidades y Exposiciones Comunes.
A nuestros efectos, un CVE es un código que identifica una vulnerabilidad del software. Tiene la forma CVE-YYYY-Ndonde AAAA es el año en que se asignó o hizo público el ID, y N es un número de secuencia de longitud arbitraria. Una organización denominada Mitre coordina la Lista CVE.
Evidentemente, un CVE no se define por su ID, sino por sus detalles. Varias organizaciones se ocupan de estos detalles, pero la que yo utilizaré es la más conocida, la National Vulnerability Database (NVD), gestionada por el National Institute of Standards and Technology (NIST). Cualquiera puede descargar gratuitamente sus datos CVE.
El NIST tiene unos sencillos gráficos de barras que muestran cómo varía la gravedad de las vulnerabilidades por año. Son gráficos de todas las CVE de software (no sólo las de Linux), desde 2001 hasta el año en curso. Quiero algo similar, pero sólo para las vulnerabilidades de Linux, y también desglosado por versión del kernel.
¿Qué hay en un CVE?
Antes de cargar y consultar los archivos de vulnerabilidad en formato JSON, déjame mostrarte lo que contienen. (Existe un esquema de especificación de archivos, pero tiene muchos detalles que no necesitamos conocer). Cada archivo CVE del NVD contiene un año de CVEs (del 1 de enero al 31 de diciembre). Esta es la estructura básica de una entrada CVE.
-
La primera sección JSON es una cabecera, que incluye el formato de los datos, la versión, el número de registros y una marca de tiempo.
-
El resto es un gran conjunto,
CVE_Itemscon estos subelementos:cveproblemtypereferencesdescriptionconfigurationsimpact- y dos campos de fecha,
publishedDateylastModifiedDate.
El que interesa es
configurations. Contiene:nodesuna serie de:childrenuna serie de:cpe_matchque comprende:vulnerablecpe23Uri: A Enumeración de plataformas comunes cadena.cpe_name
Es el
cpe23Uriyimpactpartes que eventualmente consultaré.-
El bloque de impacto define la gravedad de una vulnerabilidad como un número y un nombre utilizando el Sistema Común de Puntuación de Vulnerabilidades (CVSS). (Existen dos versiones, 2.0 y 3.0. Difieren ligeramente como se muestra a continuación).
-
El número es el Escala de puntuación básica (
baseScore), un valor decimal de 0,0 a 10,0. -
El nombre (
severity) es uno de los siguientes valores: BAJO, MEDIO o ALTO (para CVSS V2.0; NINGUNO y CRÍTICO se añaden en v3.0).
-
CVSS v2.0 frente a v3.0
Las dos versiones difieren en cómo asignan la puntuación base a la gravedad. (La siguiente tabla procede de la página CVSS de NVD).
| Clasificación CVSS v2.0 | Clasificación CVSS v3.0 | ||
|---|---|---|---|
| Gravedad | Escala de puntuación básica | Gravedad | Escala de puntuación básica |
| Ninguno | 0.0 | ||
| Bajo | 0.0-3.9 | Bajo | 0.1-3.9 |
| Medio | 4.0-6.9 | Medio | 4.0-6.9 |
| Alta | 7.0-10.0 | Alta | 7.0-8.9 |
| Crítica | 9.0-10.0 | ||
Ahora configuraré CouchDB, cargaré los datos y los consultaré con Mango.
Ejecutar CouchDB mediante Docker
-
Consigue Docker para tu plataforma.
-
Copia y pega estos comandos en un terminal y ejecútalos. (A partir de ahora, asumiré que puedes reconocer un comando cuando lo veas y que sabes qué hacer con él).
sudo docker run -d
-p 5984:5984
-e COUCHDB_USER=admin
-e COUCHDB_PASSWORD=contraseña
-name couchdb couchdb- Usaré
passwordaquí. Elige el tuyo, pero vigila dónde se utiliza a partir de ahora. - Si prefieres instalar CouchDB de forma nativa (como una instalación de aplicación normal, en lugar de dentro de un contenedor), consulta docs.couchdb.org.
- Usaré
-
Abra un navegador web y vaya a http://localhost:5984/_utils
-
Inicie sesión con las credenciales utilizadas en el comando Docker (los valores de
COUCHDB_USERyCOUCHDB_PASSWORD). -
En el panel Bases de datos, seleccione Crear base de datos.
-
En Nombre de la base de datosintroduzca
nvd(o el nombre que elija para la base de datos). -
En Particionamiento, seleccione No particionado.
- Haga clic en Crear.
Importar datos CVE a CouchDB
- Compruebe que curl y jq están en su sistema (o instálelos si no es así).
| curl -version || sudo apt install -y curl jq -version || sudo apt install -y jq |
- Instala Node.js y la herramienta couchimport.
| sudo apt-get install -y npm npm install -g couchimport |
- Descargar archivos de datos JSON de CVE.
| VERS=“1.1” R=“https://nvd.nist.gov/feeds/json/cve/${VERS}/” for YEAR in $(seq 2009 $(date +%Y)) do FILE=$(printf “nvdcve-${VERS}-%s.json.gz” $YEAR) URL=“${R}${FILE}“ echo “Downloading ${URL} to ${FILE}“ curl ${URL} –output ${FILE} –progress-bar –retry 10 done |
-
- Ajusta el intervalo de años según tus intereses. NVD tiene datos desde 2002.
- La versión cambia de vez en cuando. Compruebe https://nvd.nist.gov/vuln/data-feeds y ajuste VERS en consecuencia, pero compruebe si hay cambios en el formato del archivo de datos.
- Descomprime los archivos.
| gunzip *.gz |
- Importar datos CVE a la base de datos CouchDB.
| export COUCH_URL=“http://admin:password@localhost:5984” COUCH_DATABASE=“nvd” COUCH_FILETYPE=“json” COUCH_BUFFER_SIZE=100 for f in $(ls -1 nvdcve*.json); do echo “Importing ${f}“ cat ${f} | couchimport –jsonpath “CVE_Items.*” done |
-
- Cambie COUCH_DATABASE si la creó con un nombre diferente.
- Utilice la opción -preview true para realizar un simulacro.
- Si alguno falla, reduzca el tamaño de COUCH_BUFFER_SIZE. El valor predeterminado es 500, pero (para mí) la importación de datos de 2020 falla a menos que se reduzca el tamaño del búfer.
- Más información sobre couchimport.
- Compruebe que el número de registros de la base de datos es el mismo que el de los ficheros. (Los recuentos de estos dos comandos deben ser iguales).
| grep CVE_data_numberOfCVEs nvdcve*.json | cut -d‘:’ -f3 | tr –cd ‘[:digit:][:cntrl:]’ | awk ‘{s+=$1} END {print s}’ |
| curl -sX GET ${URL_COUCH}/nvd | jq '.doc_count' |
-
- Si los recuentos difieren, compruebe la salida del paso anterior y busque fallos de importación.
Ejecutar una consulta Mango en Fauxton
Para facilitar esta primera consulta, usaré Fauxton, la interfaz de usuario de CouchDB basada en navegador. Pero no te sientas demasiado cómodo con ella, porque en las partes 2 y 3 trabajaré únicamente en la línea de comandos.
- En un navegador, vaya a: http://localhost:5984/_utils/#database/nvd/_find
Fauxton cerrará la sesión después de un periodo de inactividad. Si esto ocurre, cierre la sesión y vuelva a entrar, vaya a Bases de datos y seleccione la base de datos nvd (si ese es el nombre que utilizó), a continuación, Ejecutar una consulta con Mango. - Elimine el contenido del panel de consulta de Mango y, a continuación, copie y pegue este texto de consulta en él:
| { “selector”: { “configurations.nodes”: { “$elemMatch”: { “operator”: “OR”, “cpe_match”: { “$elemMatch”: { “cpe23Uri”: { “$regex”: “linux_kernel” } } } } }, “publishedDate”: { “$gte”: “2021-01-01”, “$lte”: “2021-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } |
- Configure Documentos por página en su valor más alto.
- Haga clic en Ejecutar consulta.
El resultado es una lista de los identificadores CVE de las vulnerabilidades del núcleo Linux para todas las severidades y versiones del núcleo, asignados o publicados en 2021.
Deberes
- Copie y pegue el cve.CVE_data_meta.ID en la página de búsqueda de NVD para ver los detalles de cualquier CVE.
- Experimente con distintos intervalos de fechas. Por ejemplo, para empezar en enero de 2019, sustituya el elemento publishedDate por:
“publishedDate”: {
“$gte“: “2019-01-01”,
“$lte“: “2019-12-31”
}
Enhorabuena. Ahora eres el orgulloso propietario de una base de datos CouchDB abultada con más de una década (o lo que hayas elegido) de CVEs. Recuerda, la base de datos contiene datos para todo el software de todos los vendedores.
A continuación, añadiré selectores para la gravedad y la versión del núcleo, ejecutaré las consultas y trazaré los resultados.
Parte 2
Preliminares
Crea algunos directorios para tenerlo todo controlado.
| mkdir bin qry img out |
- Los usaré así:
- bin: scripts;
- qry: Archivos de consulta Mango;
- img: imágenes de gráficos;
- out: resultado de las consultas.
Instale Gnuplot.
| sudo apt install -y gnuplot |
A continuación, analizaré cómo varía el número de vulnerabilidades del núcleo de Linux año tras año. Para ello, añadiré parámetros utilizando tokens printf en las consultas de Mango, con valores sustituidos en tiempo de ejecución. (Más adelante, también añadiré parámetros para la versión del kernel.) Para mantener las cosas rápidas y sencillas, usaré la API POST de CouchDB para enviar consultas en la línea de comandos.
Consulta 1a - CVE del núcleo Linux por año
Ejecute esto para crear un archivo de consulta Mango:
| cat<<EOF>qry/1-linux-kernel-cves-by-year.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Corre esto.
| para AÑO en $(seq 2009 $(fecha +%Y)); haga echo -en "$AÑOt" printf "$(cat qry/1-linux-kernel-cves-por-año.json)" $AÑO AÑO | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find -header "Content-Type:application/json" | jq '.docs | length' hecho | tee out/1-linux-kernel-cves-by-year.tsv |
-
- Esto ejecuta la consulta en un bucle para cada año del intervalo (línea 1), e imprime los resultados tanto en la consola como en out/1-linux-kernel-cves-by-year.tsv (que utilizaré para los gráficos).
- Cambia el intervalo de años para adaptarlo a tus intereses o para que coincida con lo que importaste en la Parte 1.
- Si no obtienes ningún resultado, comprueba el archivo de consulta(qry/1-linux-kernel-cves-by-year.json) y tus credenciales de CouchDB (admin/contraseña).
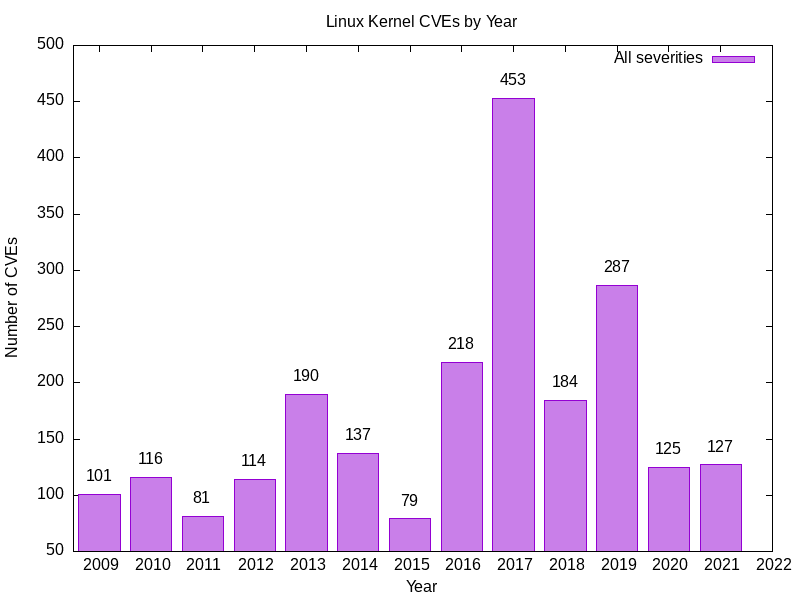
Este es el resultado que obtengo.
2009 101
2010 116
2011 81
2012 114
2013 190
2014 137
2015 79
2016 218
2017 453
2018 184
2019 287
2020 125
2021 127
- Este es el número de vulnerabilidades del núcleo Linux de cada año.
- Algunas de sus cifras pueden ser superiores, ya que las vulnerabilidades pueden registrarse retrospectivamente.
Ejecute esto para crear un script gnuplot en bin/1-linux-kernel-cves-by-year.gnuplot:
| cat<<EOF>bin/1-linux-kernel-cves-by-year.gnuplot reset set terminal png size 800,600 set output ‘img/1-linux-kernel-cves-by-year.png’ set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right set title ‘Linux Kernel CVEs by Year’ set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [2008.5:*] [] ‘out/1-linux-kernel-cves-by-year.tsv’ w boxes t ‘All severities’, ‘out/1-linux-kernel-cves-by-year.tsv’ u 1:($2+15):2 w labels t ” EOF |
- Ejecute esto para crear un archivo de imagen en img/1-linux-kernel-cves-by-year.png:
| gnuplot -c bin/1-linux-kernel-cves-por-año.gnuplot |
- Abre img/1-linux-kernel-cves-by-year.png en tu visor de imágenes favorito. Aquí está el mío.
Comentario
Eso son muchas vulnerabilidades del kernel de Linux. 2017 fue un año espectacularmente bueno/malo para las vulnerabilidades del núcleo de Linux.
Cuando lo vi me preocupé, así que lo contrasté con otras fuentes, entre ellas CVEDetails. Las cifras cuadran bastante bien.
Año Mina CVDetalles
2009 101 104
2010 116 118
2011 81 81
2012 114 114
2013 190 186
2014 137 128
2015 79 79
2016 218 215
2017 453 449
2018 184 178
2019 287 289
2020 125 126
2021 127 130
Cualquier diferencia puede explicarse por las observaciones de los detalles del CVE:
"...Los datos CVE presentan incoherencias que afectan [a la] exactitud de los datos mostrados... Por ejemplo, las vulnerabilidades relacionadas con Oracle Database 10g podrían haberse definido para los productos 'Oracle Database', 'Oracle Database10g', 'Database10g', 'Oracle 10g' y similares."
En otras palabras, los datos del CVE del NVD no son del todo precisos. (Más sobre esto más adelante).
Este gráfico muestra los recuentos totales de CVE agregados en todas las severidades de CVE. Para desglosar los resultados por gravedad, añadiré un selector a la consulta de Mango.
Consulta 1b - CVE del núcleo Linux por año y gravedad
- Ejecute esto para crear qry/cve-1b.json (una copia de la consulta 1a con un parámetro de gravedad añadido):
| cat<<EOF>qry/2-linux-kernel-cves-by-year-and-severity.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “impact.baseMetricV2.severity”: “%s”, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Corre esto.
| export OUT=“2-linux-kernel-cves-by-year-and-severity” SEVS=(LOW MEDIUM HIGH) (IFS=$‘t’; echo -e “YEARt${SEVS[*]}“ | tee out/${OUT}.tsv); for YEAR in $(seq 2009 $(date +%Y)); do RES=() echo -en “$YEARt” for SEV in ${SEVS[*]}; do RES+=($(printf “$(cat qry/${OUT}.json)“ ${SEV} ${YEAR} ${YEAR} | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
Este es mi resultado.
YEAR LOW MEDIUM HIGH
2009 11 51 39
2010 37 47 32
2011 19 41 21
2012 24 66 24
2013 46 126 18
2014 20 87 30
2015 17 44 18
2016 25 114 79
2017 73 91 289
2018 36 93 55
2019 47 151 89
2020 38 64 23
2021 44 59 24
- Ejecute esto para crear un script gnuplot en bin/cve-1b.gnuplot:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set style data histograms set style histogram rowstacked set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right title “Severity” set title “Linux kernel CVEs” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot “out/`echo ${OUT}`.tsv” u ($2):xtic(1) t col, ” u ($3):xtic(1) t col, ” u ($4):xtic(1) t col, ” u ($0-1):($2+10):(sprintf(“%d”,$2)) with labels t ”, ” u ($0-1):($2+$3+10):(sprintf(“%d”,$3)) with labels t ”, ” u ($0-1):($2+$3+$4+10):(sprintf(“%d”,$4)) with labels t ” EOF |
- Ejecute esto para crear un archivo de imagen en img/cve-1b.png.
| gnuplot -c bin/${OUT}.gnuplot |
Aquí está la mía.
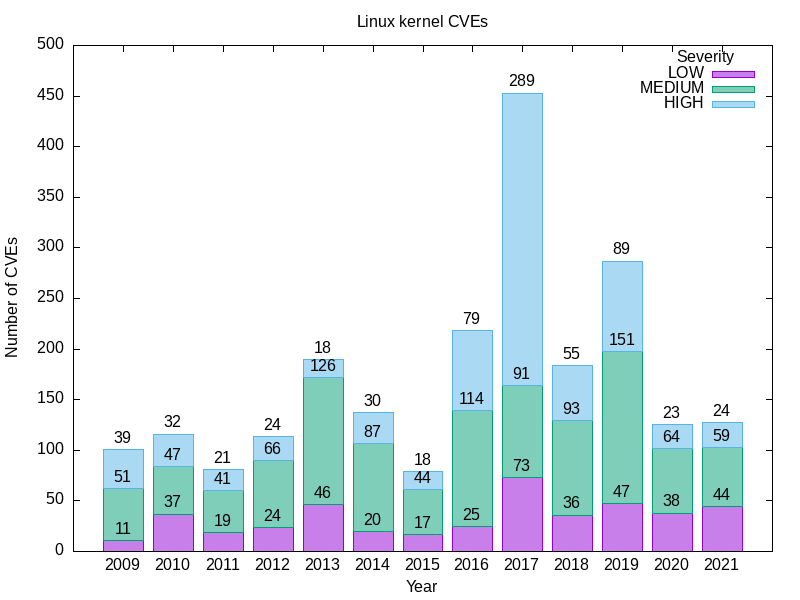
Notas sobre la gravedad
-
- La consulta 1b utiliza la versión 2 de CVSS en lugar de la versión 3, más reciente. Hay una razón para ello. La versión 3 de CVSS se introdujo en diciembre de 2015; los CVE anteriores a esa fecha solo pueden seleccionarse utilizando el esquema CVSS de la versión 2.
- Las versiones 2 y 3 de CVSS tienen representaciones numéricas y textuales de la gravedad. La numérica es más precisa, mientras que la textual es más tosca, pero más fácil de relacionar. Para simplificar, voy a utilizar el esquema textual. Más adelante cambiaré al esquema numérico, por motivos de precisión.
La consulta 1b ofrece una imagen más nítida que la consulta 1a, pero no menos impactante. Por ejemplo, compare las proporciones relativas de vulnerabilidades de gravedad ALTA del núcleo de Linux con las de antes y después de 2016.
Podría ser que muchas de estas vulnerabilidades estén concentradas en unas pocas versiones del kernel. No lo sabré hasta que modifique la consulta para seleccionar la versión, así como el año y la gravedad. Eso será lo próximo.
Parte 3
Aquí, en la Parte 3, desarrollo esa consulta básica de Mango para ver cómo varía el número de vulnerabilidades del núcleo de Linux según la versión del núcleo.
Como hay tantas versiones, las consultas y los comandos empiezan a complicarse y tardan más en completarse. Así que, por ahora, sólo variaré el año y la versión del núcleo. La severidad sigue siendo un parámetro, pero consultaré los resultados para todas las severidades.
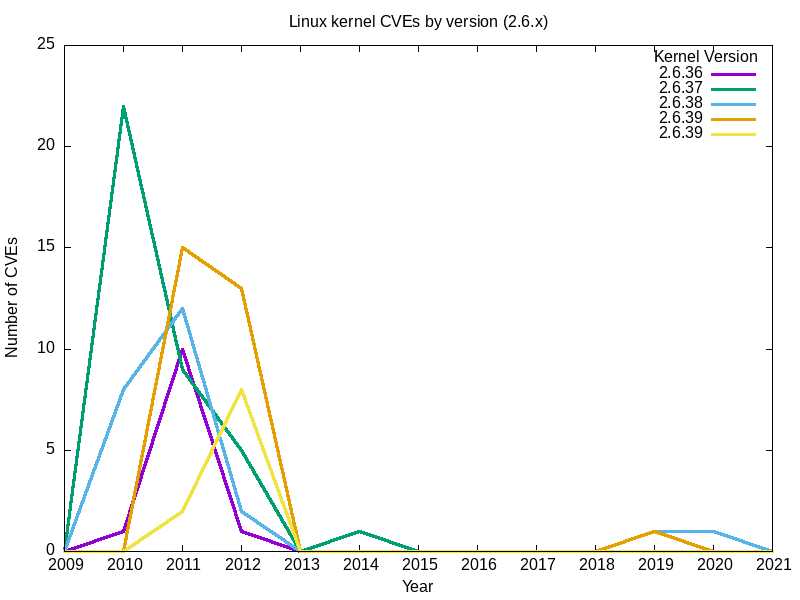
Empezaré analizando las cinco últimas versiones (2.6.35 a 2.6.39) de la famosa rama 2.6.x del núcleo Linux.
Consulta 2 - CVE del núcleo Linux por año y versión del núcleo
- Ejecútelo para crear un archivo de consulta:
| export QRY=“3-linux-kernel-cves-by-year-and-version” cat<<EOF>qry/${QRY}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Corre esto.
| export VERS_MAJOR=2.6 VERS_MINOR_START=35 VERS_MINOR_STOP=39 YEAR_START=2009 YEAR_STOP=$(date +%Y) VERSIONS=() COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” export OUT=“${QRY}_${VERS_MAJOR}.x” for VERS_MINOR in $(seq ${VERS_MINOR_START} ${VERS_MINOR_STOP}); do VERSIONS+=(${VERS_MAJOR}.${VERS_MINOR}); done (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
- La salida:
| 2.6.35 2.6.36 2.6.37 2.6.38 2.6.39 2009 0 0 0 0 0 2010 1 22 8 0 0 2011 10 9 12 15 2 2012 1 5 2 13 8 2013 0 0 0 0 0 2014 1 1 0 0 0 2015 0 0 0 0 0 2016 0 0 0 0 0 2017 0 0 0 0 0 2018 0 0 0 0 0 2019 0 0 1 1 0 2020 0 0 1 0 0 2021 0 0 0 0 0 |
- Ejecute esto para crear el script gnuplot:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version (`echo ${VERS_MAJOR}`.x)” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/`echo ${OUT}`.tsv” using 1:c with lines lw 3 EOF |
- Ejecute gnuplot para crear el archivo de imagen.
| gnuplot -c bin/${OUT}.gnuplot |
- Aquí está la mía.
Script para CVEs del kernel Linux 3.x, 4.x, 5.x por año y versión
He aquí un script que combina los tres últimos comandos en un solo bloque, y utiliza variables de entorno para consultar las cinco últimas versiones de las otras ramas principales del núcleo Linux.
Guarda el código en un archivo, hazlo ejecutable y ejecútalo. Y espera.
| #!/bin/bash # Script to chart Linux kernel CVEs for kernel versions # 3.x, 4.x, 5.x. # You must have loaded a CouchDB database with CVE # data as described here: # https://blog.kernelcare.com/linux-kernel-cve-data-analysis-part-1-importing-into-couchdb # Parallel arrays for Linux kernel versions: # 3.0-3.19 (2011-DATE) # 4.0-4.20 (2015-DATE) # 5.0-5.12 (2019-DATE) VERS_MAJOR=(3 4 5) VERS_MINOR_START=(0 0 0) VERS_MINOR_STOP=(19 20 12) YEAR_START=(2011 2015 2019) YEAR_STOP=$(date +%Y) # admin/password are CouchDB admin login credentials COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” ## # Construct version string from args # and set VERSIONS. # Args: # 1: Major version number # 2: Minor version start number # 3: Minor version stop number build_versions() { VERSIONS=() for VERS_MINOR in $(seq ${2} ${3}); do VERSIONS+=(${1}.${VERS_MINOR}) done } ## # Write a query file to qry subdir # Args: # 1: Name of query file without extension write_query() { cat<<EOF>qry/${1}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF } ## # Run the query # run_query() { (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START[$i]} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv } # Run a gnuplot script with values supplied # by: # 1: Base of filename # 2: Major version number # 3: As per 1 run_gnuplot() { printf ‘ reset set terminal png size 800,600 set output “img/%s.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version %s.x” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/%s.tsv” using 1:c with lines lw 3 ‘ $1 $2 $1 | gnuplot – } main() { write_query ${QRY} for i in 0 1 2; do build_versions ${VERS_MAJOR[$i]} ${VERS_MINOR_START[$i]} ${VERS_MINOR_STOP[$i]} OUT=“${QRY}_${VERS_MAJOR[$i]}.x” run_query run_gnuplot $OUT ${VERS_MAJOR[$i]} done } main |
Estos son los gráficos resultantes.
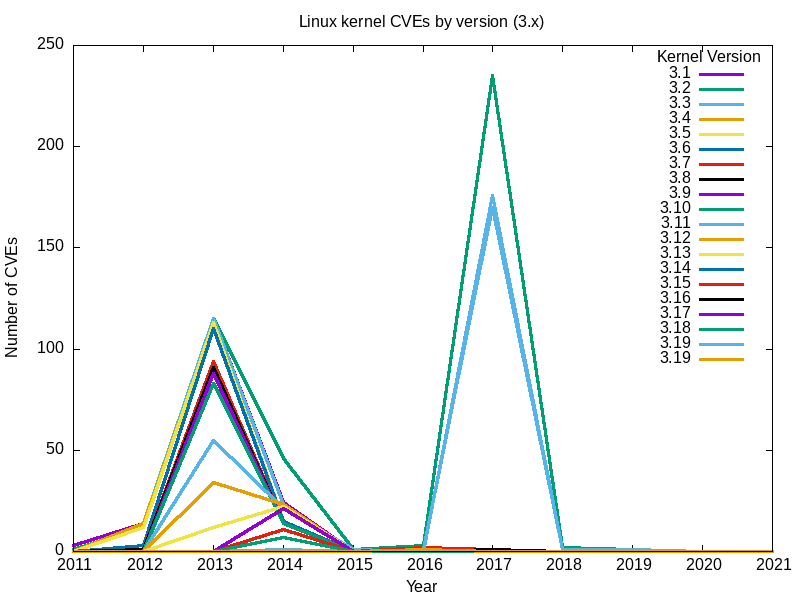
Sí, el gran repunte de 2017 se debió principalmente a las vulnerabilidades encontradas en 3.18.
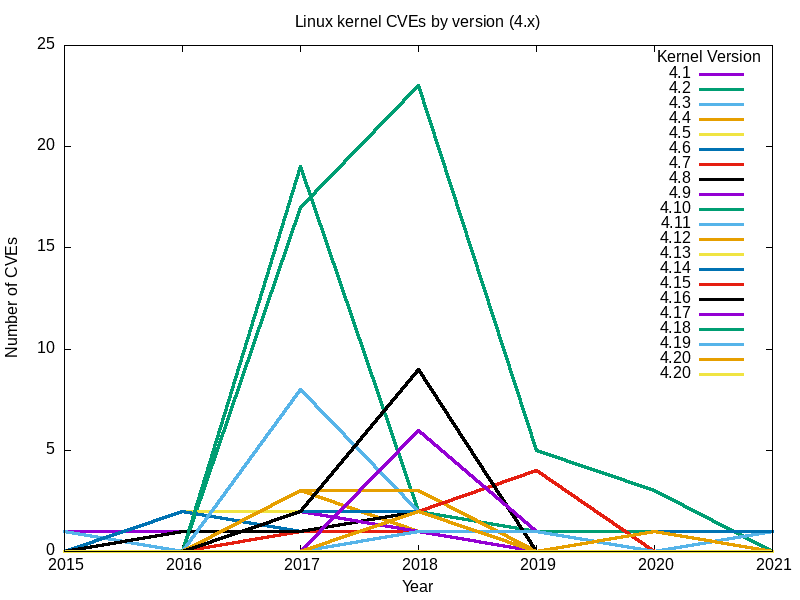
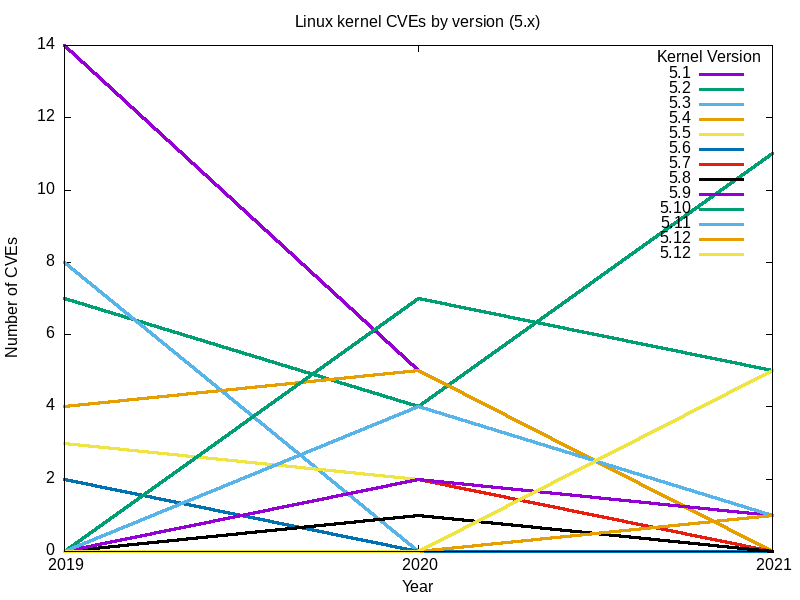
Conclusiones
-
En conjunto, el conjunto completo de gráficos de todas las ramas principales del núcleo Linux parece responder a mi pregunta original: el núcleo Linux más seguro (el que tiene menos vulnerabilidades) es el más reciente[Nota del editor: en el momento de escribir este artículo], la versión 5.12.
-
El efecto de muchas vulnerabilidades se extiende más allá de las ramas y las fechas de "Fin de vida". Por ejemplo, para 2.6, la última versión, 2.6.39, fue en mayo de 2011. La versión 2.6.39.4 fue designada "fin de vida" en agosto del mismo año. Sin embargo, los informes de vulnerabilidades no han cesado, y han aumentado desde 2016.
-
Comparar las vulnerabilidades rama por rama no es la mejor manera. Las ramas son continuas, y la versión final de una rama constituye la base de la siguiente. Por ejemplo, la 5.0 es una continuación de la rama 4.x, la 4.0 una continuación de la 3.19, y la versión final 2.6.39 de la rama 2.6 de larga duración continuó en la 3.0. La forma en que las bases de código se ramifican de esta manera significa que cada rama subsiguiente tendrá progresivamente menos errores.


