 Documentation
Documentation Connexion
ConnexionAnalyse des données CVE du noyau Linux (mise à jour)

Le 13 décembre 2021 - L'équipe de relations publiques de TuxCare
Si vous vous intéressez à la sécurité de Linux, aux vulnérabilités du noyau ou si vous avez simplement un peu de temps libre pour effectuer quelques tests, cet article est pour vous. Nous y proposons une version actualisée d'une méthodologie que vous pouvez utiliser pour extraire des données des dépôts CVE et créer votre propre analyse statistique. Découvrez quelles versions du noyau présentent le plus de vulnérabilités identifiées.
|
Note de l'éditeur: Cet article est une version mise à jour d'une série d'articles publiés dans l'ancien blog KernelCare. Depuis leur publication, le format des données sur les référentiels CVE a changé, de sorte que les instructions originales ne fonctionnent plus. Plutôt que de mettre à jour d'anciens articles qui n'auraient aucune visibilité, nous republions l'ensemble du contenu avec des instructions étape par étape fonctionnelles. Nous sommes conscients que les résultats sont quelque peu faussés du fait que certaines versions du noyau sont plus largement adoptées que d'autres, et sont donc testées de manière plus approfondie, et que les CVE ne sont pas le meilleur moyen d'affirmer le niveau de (in)sécurité d'une version donnée du noyau. Cependant, cela reste un exercice intéressant et, à tout le moins, il vous permettra d'utiliser plusieurs outils que vous n'utiliseriez peut-être jamais autrement. Vous avez maintenant un moyen de vérifier les affirmations de "tant de vulnérabilités pour tel ou tel noyau" pour vous-même, et avec ce travail de base vous pourriez, avec quelques changements, suivre les vulnérabilités d'autres projets au lieu du seul noyau. Un "merci" à Paul Jacobs, qui a soumis la version actualisée de ses articles originaux. |
Contenu
Partie 1 - Configuration et acquisition de données
Partie 2 - Filtrage des données
Partie 3 - Requêtes avancées et graphiques
Mise à jour pour 2021. Changements :
-
- Mise à jour de la syntaxe du sélecteur de requête de Mango pour la spécification CVE 1.1.
- Utilise le conteneur Docker de CouchDB.
Partie 1
Les développeurs du noyau Linux nous disent que le "meilleur" noyau Linux à utiliser est celui qui est livré avec la distribution que nous utilisons. Ou la dernière version stable. Ou la version la plus récente du support à long terme (LTS). Ou celle que nous voulons, tant qu'elle est maintenue.
Le choix est formidable, mais je préfère avoir une seule réponse ; je veux simplement la meilleure. Le problème est que, pour certaines personnes, le meilleur signifie le plus rapide. Pour d'autres, le meilleur est celui qui possède les dernières fonctionnalités, ou une fonctionnalité spécifique. Pour moi, le meilleur noyau Linux est le plus sûr.
Quel est le noyau Linux le plus sûr ?
Une façon rudimentaire de considérer la sécurité d'un logiciel est de voir combien de problèmes de sécurité apparaissent dans une version spécifique de celui-ci. (Je sais que c'est une prémisse bancale, mais faisons avec, ne serait-ce que pour en savoir plus sur les CVE et la façon de les interpréter). Appliquer cette tactique au noyau Linux signifie examiner les rapports de vulnérabilité.
C'est ce que je vais faire dans cette série de trois articles. Je vais analyser les CVE (vulnérabilités signalées) du noyau Linux pour voir s'il existe des tendances qui peuvent aider à répondre à la question suivante : quel est le meilleur (c'est-à-dire le plus sûr) noyau Linux à utiliser ?
Mais attendez, cela n'a-t-il pas déjà été fait ?
En quelque sorte.
-
Détails CVE: Un moteur de recherche de CVE. Vous pouvez trouver les CVE par gravité, produit, fournisseur, etc.
-
CVEs du noyau Linux: Également un moteur de recherche CVE, listant les ID CVE pour des versions spécifiques du noyau Linux.
-
Alexander Leonov: Bel article sur l'anatomie d'un fichier de données CVE, mais avec un accent sur les données CPE.
-
Tenable.sc: Produit commercial avec un tableau de bord d'analyse des CVE.
Alors, pourquoi faire ça ?
Parce que soit ces ressources et projets ne répondent pas à ma question, soit ils coûtent de l'argent.
Et puis, je veux apprendre ce qu'est un CVE, ce qu'il peut me dire sur les différences (s'il y en a) entre les versions du noyau Linux, et quelles sont les limites de cette approche.
Le processus et les outils
C'est assez simple : obtenir les données, les analyser, établir un graphique des résultats.
Les outils sont gratuits et fonctionnent sur de nombreuses plateformes. Je travaillerai sur Debian Linux, et je suppose que vous n'êtes pas effrayé par la vue d'un terminal nu.
Pour que vous sachiez à quoi vous attendre, voici les principales étapes.
-
Utilisez Docker pour exécuter la dernière version d'Apache CouchDB. (Il s'agira d'une configuration à un seul nœud - je veux explorer les données, sans m'embourber dans l'administration).
-
Téléchargez les données NVD (sous forme de fichiers JSON) et importez tous les enregistrements CVE, pas seulement ceux concernant le noyau Linux. (De cette façon, il est plus facile de sélectionner les données pertinentes au moment de la requête que d'analyser et d'extraire les enregistrements des fichiers JSON).
-
Utilisez Mango pour interroger les données.
Tout d'abord, voici un bref aperçu de ce qu'est un CVE et de ce que contient un enregistrement CVE.
Qu'est-ce qu'un CVE ?
CVE est l'abréviation de Common Vulnerability and Exposures (vulnérabilité et exposition communes).
Pour notre propos, un CVE est un code qui identifie une vulnérabilité logicielle. Il se présente sous la forme CVE-YYYY-Noù YYYY est l'année où l'identifiant a été attribué ou rendu public, et N est un numéro de séquence de longueur arbitraire. Une organisation appelée Mitre coordonne le Liste CVE.
En clair, un CVE n'est pas défini par son ID, mais par ses détails. Plusieurs organisations s'occupent de ces détails, mais celle que je vais utiliser est la plus connue, la National Vulnerability Database (NVD ), gérée par le National Institute of Standards and Technology (NIST). Tout le monde peut télécharger gratuitement ses données CVE.
Le NIST propose des diagrammes à barres simples qui montrent comment la gravité des vulnérabilités varie selon les années. Ce sont des graphiques de tous les CVEs logiciels (pas seulement ceux de Linux), de 2001 à cette année. Je veux quelque chose de similaire, mais seulement pour les vulnérabilités de Linux, et ventilé par version du noyau, aussi.
Qu'y a-t-il dans un CVE ?
Avant de charger et d'interroger les fichiers de vulnérabilité au format JSON, laissez-moi vous montrer ce qu'ils contiennent. (Il existe un schéma de spécification des fichiers, mais il comporte beaucoup de détails dont nous n'avons pas besoin de connaître). Chaque fichier NVD CVE contient une année de CVE (du 1er janvier au 31 décembre). Voici la structure de base d'une entrée CVE.
-
La première section JSON est un en-tête, comprenant le format des données, la version, le nombre d'enregistrements et un horodatage.
-
Le reste est un grand tableau,
CVE_Itemsavec ces sous-éléments :cveproblemtypereferencesdescriptionconfigurationsimpact- et deux champs de date,
publishedDateetlastModifiedDate.
Celui qui nous intéresse est le suivant
configurations. Il contient :nodesun tableau de :childrenun tableau de :cpe_matchcomprenant :vulnerablecpe23Uri: A Enumération des plates-formes communes chaîne.cpe_name
C'est le
cpe23Urietimpactdes parties que je vais éventuellement interroger.-
Le bloc d'impact définit la gravité d'une vulnérabilité sous la forme d'un nombre et d'un nom en utilisant le Common Vulnerability Scoring System (CVSS). (Il existe deux versions, 2.0 et 3.0. Elles diffèrent légèrement comme indiqué ci-dessous).
-
Ce numéro est le Gamme des scores de base (
baseScore), une valeur décimale comprise entre 0,0 et 10,0. -
Le nom (
severity) est une valeur parmi LOW, MEDIUM ou HIGH (pour CVSS V2.0 ; NONE et CRITICAL sont ajoutés dans la v3.0).
-
CVSS v2.0 vs v3.0
Les deux versions diffèrent dans la façon dont elles font correspondre le score de base à la gravité. (Le tableau ci-dessous provient de la page CVSS de NVD).
| Évaluations CVSS v2.0 | Évaluations CVSS v3.0 | ||
|---|---|---|---|
| Gravité | Gamme des scores de base | Gravité | Gamme des scores de base |
| Aucun | 0.0 | ||
| Faible | 0.0-3.9 | Faible | 0.1-3.9 |
| Moyen | 4.0-6.9 | Moyen | 4.0-6.9 |
| Haut | 7.0-10.0 | Haut | 7.0-8.9 |
| Critique | 9.0-10.0 | ||
Je vais maintenant configurer CouchDB, charger les données et les interroger avec Mango.
Exécuter CouchDB via Docker
-
Obtenez Docker pour votre plateforme.
-
Copiez et collez ces commandes dans un terminal et exécutez-les. (A partir de maintenant, je supposerai que vous savez reconnaître une commande quand vous en voyez une et que vous savez quoi faire avec).
sudo docker run -d
-p 5984:5984
-e COUCHDB_USER=admin
-e COUCHDB_PASSWORD=mot de passe
-name couchdb couchdb- Je vais utiliser
passwordici. Choisissez le vôtre, mais faites attention à l'usage que vous en ferez à partir de maintenant. - Si vous préférez installer CouchDB de manière native (en tant qu'installation d'une application normale, plutôt qu'à l'intérieur d'un conteneur), consultez docs.couchdb.org.
- Je vais utiliser
-
Ouvrez un navigateur web et allez sur http://localhost:5984/_utils
-
Connectez-vous avec les informations d'identification utilisées dans la commande Docker (les valeurs de l'option
COUCHDB_USERetCOUCHDB_PASSWORD). -
Dans le volet Bases de données, sélectionnez Créer une base de données.
-
Sur Nom de la base de données, entrez
nvd(ou le nom de la base de données de votre choix). -
Pour Partitionnement, sélectionnez Non-partitionné.
- Cliquez sur Créer.
Importer les données CVE dans CouchDB
- Vérifiez que curl et jq sont sur votre système (ou installez-les si ce n'est pas le cas).
| curl -version || sudo apt install -y curl jq -version || sudo apt install -y jq |
- Installez Node.js et l'outil couchimport.
| sudo apt-get install -y npm npm install -g couchimport |
- Télécharger les fichiers de données CVE JSON.
| VERS=“1.1” R=“https://nvd.nist.gov/feeds/json/cve/${VERS}/” for YEAR in $(seq 2009 $(date +%Y)) do FILE=$(printf “nvdcve-${VERS}-%s.json.gz” $YEAR) URL=“${R}${FILE}“ echo “Downloading ${URL} to ${FILE}“ curl ${URL} –output ${FILE} –progress-bar –retry 10 done |
-
- Ajustez la fourchette d'années en fonction de vos intérêts. NVD a des données à partir de 2002.
- La version change de temps en temps. Consultez https://nvd.nist.gov/vuln/data-feeds et définissez VERS en conséquence, mais vérifiez les changements de format des fichiers de données.
- Décompressez les fichiers.
| gunzip *.gz |
- Importez les données CVE dans la base de données CouchDB.
| export COUCH_URL=“http://admin:password@localhost:5984” COUCH_DATABASE=“nvd” COUCH_FILETYPE=“json” COUCH_BUFFER_SIZE=100 for f in $(ls -1 nvdcve*.json); do echo “Importing ${f}“ cat ${f} | couchimport –jsonpath “CVE_Items.*” done |
-
- Changez COUCH_DATABASE si vous l'avez créé avec un nom différent.
- Utilisez l'option -preview true pour faire un essai.
- Si l'un d'entre eux échoue, réduisez la taille de COUCH_BUFFER_SIZE. La valeur par défaut est de 500 mais (pour moi) l'importation des données de 2020 échoue si la taille du tampon n'est pas réduite.
- En savoir plus sur couchimport.
- Vérifiez que le nombre d'enregistrements dans la base de données est le même que dans les fichiers. (Les comptes obtenus à partir de ces deux commandes devraient être les mêmes).
| grep CVE_data_numberOfCVEs nvdcve*.json | cut -d‘:’ -f3 | tr –cd ‘[:digit:][:cntrl:]’ | awk ‘{s+=$1} END {print s}’ |
| curl -sX GET ${COUCH_URL}/nvd | jq .doc_count' |
-
- Si les comptes diffèrent, vérifiez la sortie de l'étape précédente et recherchez les échecs d'importation.
Exécuter une requête Mango à Fauxton
Pour faciliter cette première requête, je vais utiliser Fauxton, l'interface utilisateur de CouchDB basée sur le navigateur. Mais ne vous y habituez pas trop, car dans les parties 2 et 3, je travaillerai uniquement en ligne de commande.
- Dans un navigateur, allez sur : http://localhost:5984/_utils/#database/nvd/_find
Fauxton vous déconnectera après une période d'inactivité. Si cela se produit, déconnectez-vous et reconnectez-vous, allez dans Bases de données, sélectionnez la base de données nvd (si c'est le nom que vous avez utilisé), puis exécutez une requête avec Mango. - Supprimez le contenu du volet de requête Mango, puis copiez et collez-y ce texte de requête :
| { “selector”: { “configurations.nodes”: { “$elemMatch”: { “operator”: “OR”, “cpe_match”: { “$elemMatch”: { “cpe23Uri”: { “$regex”: “linux_kernel” } } } } }, “publishedDate”: { “$gte”: “2021-01-01”, “$lte”: “2021-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } |
- Réglez le paramètre Documents par page sur sa valeur la plus élevée.
- Cliquez sur Exécuter la requête.
Le résultat est une liste des ID CVE des vulnérabilités du noyau Linux pour toutes les gravités et versions du noyau, attribuées ou publiées en 2021.
Devoirs à domicile
- Copiez et collez l'identifiant cve.CVE_data_meta.ID dans la page de recherche NVD pour voir les détails de tout CVE.
- Expérimentez avec différentes plages de dates. Par exemple, pour commencer en janvier 2019, remplacez l'élément publishedDate par :
“publishedDate”: {
“$gte“: “2019-01-01”,
“$lte“: “2019-12-31”
}
Félicitations. Vous êtes maintenant l'heureux propriétaire d'une base de données CouchDB contenant plus d'une décennie (ou ce que vous avez choisi) de CVEs. N'oubliez pas que la base de données contient des données pour tous les logiciels de tous les fournisseurs.
Ensuite, j'ajouterai des sélecteurs pour la gravité et la version du noyau, j'exécuterai les requêtes et j'établirai un graphique des résultats.
Partie 2
Préliminaires
Créez des répertoires pour garder une trace de tout.
| mkdir bin qry img out |
- Je vais les utiliser comme ça :
- bin: scripts ;
- qry: Fichiers de requêtes Mango ;
- img: images des graphiques ;
- out: sortie des requêtes.
Installez Gnuplot.
| sudo apt install -y gnuplot |
Ensuite, j'examinerai comment le nombre de vulnérabilités du noyau Linux varie d'une année sur l'autre. Pour ce faire, j'ajouterai des paramètres à l'aide de tokens printf dans les requêtes Mango, les valeurs étant substituées au moment de l'exécution. () Pour que les choses restent simples et rapides, j'utiliserai l'API POST de CouchDB pour soumettre les requêtes en ligne de commande.
Requête 1a - CVEs du noyau Linux par année
Exécutez ceci pour créer un fichier de requête Mango :
| cat<<EOF>qry/1-linux-kernel-cves-by-year.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Fais ça.
| pour ANNÉE dans $(seq 2009 $(date +%Y)) ; faire echo -en "$YEARt" printf "$(cat qry/1-linux-kernel-cves-by-year.json)" ANNÉE ANNÉE | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find -header "Content-Type:application/json" | jq '.docs | longueur' terminé | tee out/1-linux-kernel-cves-by-year.tsv |
-
- Ceci exécute la requête en boucle pour chaque année de l'intervalle (ligne 1), et imprime les résultats à la fois sur la console et dans out/1-linux-kernel-cves-by-year.tsv (que j'utiliserai pour le graphique).
- Modifiez la fourchette d'années en fonction de vos intérêts ou de ce que vous avez importé dans la première partie.
- Si vous n'obtenez aucun résultat, vérifiez le fichier de requête(qry/1-linux-kernel-cves-by-year.json) et vos informations d'identification CouchDB (admin/mot de passe).
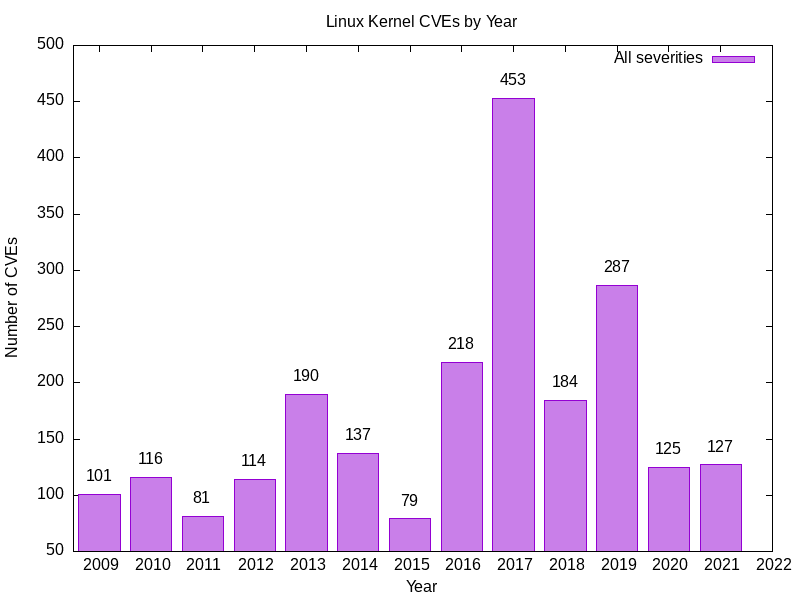
Voici le résultat que j'obtiens.
2009 101
2010 116
2011 81
2012 114
2013 190
2014 137
2015 79
2016 218
2017 453
2018 184
2019 287
2020 125
2021 127
- Il s'agit du nombre de vulnérabilités du noyau Linux pour chaque année.
- Certains de vos chiffres peuvent être plus élevés, car les vulnérabilités peuvent être enregistrées rétrospectivement.
Exécutez ceci pour créer un script gnuplot dans bin/1-linux-kernel-cves-by-year.gnuplot:
| cat<<EOF>bin/1-linux-kernel-cves-by-year.gnuplot reset set terminal png size 800,600 set output ‘img/1-linux-kernel-cves-by-year.png’ set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right set title ‘Linux Kernel CVEs by Year’ set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [2008.5:*] [] ‘out/1-linux-kernel-cves-by-year.tsv’ w boxes t ‘All severities’, ‘out/1-linux-kernel-cves-by-year.tsv’ u 1:($2+15):2 w labels t ” EOF |
- Exécutez ceci pour créer un fichier image dans img/1-linux-kernel-cves-by-year.png:
| gnuplot -c bin/1-linux-kernel-cves-by-year.gnuplot |
- Ouvrez img/1-linux-kernel-cves-by-year.png dans votre visionneur d'images préféré. Voici le mien.
Commentaire
Cela fait beaucoup de vulnérabilités du noyau Linux. 2017 a été une année spectaculairement bonne/mauvaise pour les vulnérabilités du noyau Linux.
J'étais inquiet quand j'ai vu cela, alors j'ai fait une vérification croisée avec d'autres sources, dont CVEDetails. Les chiffres s'accordent plutôt bien.
Année Mine CVEDétails
2009 101 104
2010 116 118
2011 81 81
2012 114 114
2013 190 186
2014 137 128
2015 79 79
2016 218 215
2017 453 449
2018 184 178
2019 287 289
2020 125 126
2021 127 130
Les différences éventuelles peuvent être expliquées par les observations de CVE Details :
"...les données CVE présentent des incohérences qui affectent [la] précision des données affichées... Par exemple, les vulnérabilités liées à Oracle Database 10g pourraient avoir été définies pour les produits 'Oracle Database', 'Oracle Database10g', 'Database10g', 'Oracle 10g' et similaires."
En d'autres termes, les données CVE du NVD ne sont pas totalement exactes. (Nous y reviendrons plus tard).
Ce graphique montre le nombre total de CVE agrégés à travers toutes les sévérités de CVE. Pour ventiler les résultats par gravité, je vais ajouter un sélecteur à la requête Mango.
Requête 1b - CVEs du noyau Linux par année et gravité
- Exécutez ceci pour créer qry/cve-1b.json (une copie de la requête 1a avec un paramètre de sévérité ajouté) :
| cat<<EOF>qry/2-linux-kernel-cves-by-year-and-severity.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “impact.baseMetricV2.severity”: “%s”, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Fais ça.
| export OUT=“2-linux-kernel-cves-by-year-and-severity” SEVS=(LOW MEDIUM HIGH) (IFS=$‘t’; echo -e “YEARt${SEVS[*]}“ | tee out/${OUT}.tsv); for YEAR in $(seq 2009 $(date +%Y)); do RES=() echo -en “$YEARt” for SEV in ${SEVS[*]}; do RES+=($(printf “$(cat qry/${OUT}.json)“ ${SEV} ${YEAR} ${YEAR} | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
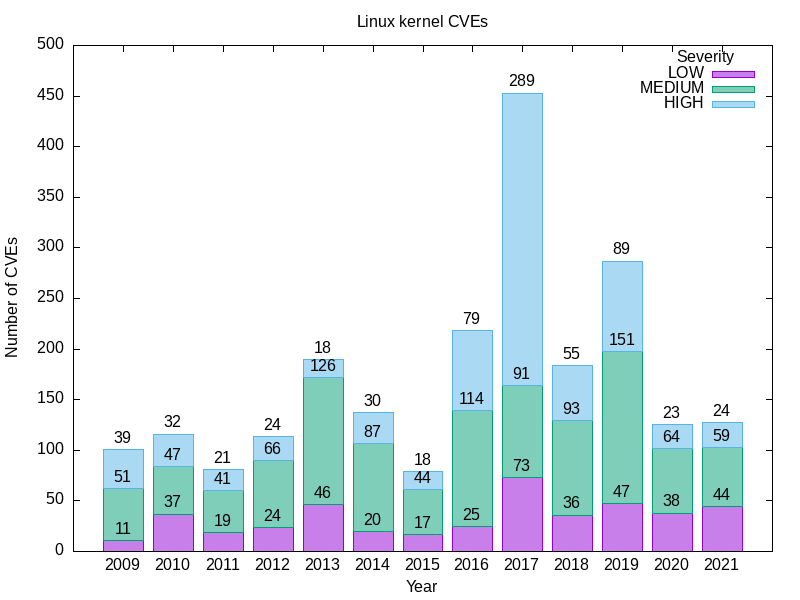
Voici mon résultat.
YEAR LOW MEDIUM HIGH
2009 11 51 39
2010 37 47 32
2011 19 41 21
2012 24 66 24
2013 46 126 18
2014 20 87 30
2015 17 44 18
2016 25 114 79
2017 73 91 289
2018 36 93 55
2019 47 151 89
2020 38 64 23
2021 44 59 24
- Exécutez ceci pour créer un script gnuplot dans bin/cve-1b.gnuplot:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set style data histograms set style histogram rowstacked set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right title “Severity” set title “Linux kernel CVEs” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot “out/`echo ${OUT}`.tsv” u ($2):xtic(1) t col, ” u ($3):xtic(1) t col, ” u ($4):xtic(1) t col, ” u ($0-1):($2+10):(sprintf(“%d”,$2)) with labels t ”, ” u ($0-1):($2+$3+10):(sprintf(“%d”,$3)) with labels t ”, ” u ($0-1):($2+$3+$4+10):(sprintf(“%d”,$4)) with labels t ” EOF |
- Exécutez ceci pour créer un fichier image dans img/cve-1b.png.
| gnuplot -c bin/${OUT}.gnuplot |
Voici le mien.
Notes sur la sévérité
-
- La requête 1b utilise la version 2 de CVSS plutôt que la version 3, plus récente. Il y a une raison à cela . La version 3 de CVSS a été introduite en décembre 2015 ; les CVE antérieures à cette date ne peuvent être sélectionnées qu'en utilisant le schéma CVSS version 2.
- Les versions 2 et 3 de CVSS ont toutes deux des représentations numériques et textuelles pour la gravité. La représentation numérique est plus précise, tandis que la représentation textuelle est plus grossière, mais plus facile à comprendre. Pour simplifier, j'utilise le schéma textuel. Je passerai au schéma numérique plus tard, pour plus de précision.
La requête 1b est une image plus nette que la requête 1a, mais pas moins choquante. Par exemple, comparez les proportions relatives des vulnérabilités du noyau Linux de HAUTE gravité à celles d'avant et d'après 2016.
Il se pourrait que beaucoup de ces vulnérabilités soient concentrées dans quelques versions du noyau. Je ne le saurai pas tant que je n'aurai pas modifié la requête pour sélectionner la version ainsi que l'année et la gravité. C'est à venir.
Partie 3
Dans la troisième partie, je développe cette requête de base de Mango pour étudier comment le nombre de vulnérabilités du noyau Linux varie selon la version du noyau.
Comme il existe de nombreuses versions, les requêtes et les commandes deviennent plus compliquées et prennent plus de temps. Donc, pour l'instant, je vais seulement faire varier l'année et la version du noyau. La sévérité reste un paramètre, mais je vais demander des résultats pour toutes les sévérités.
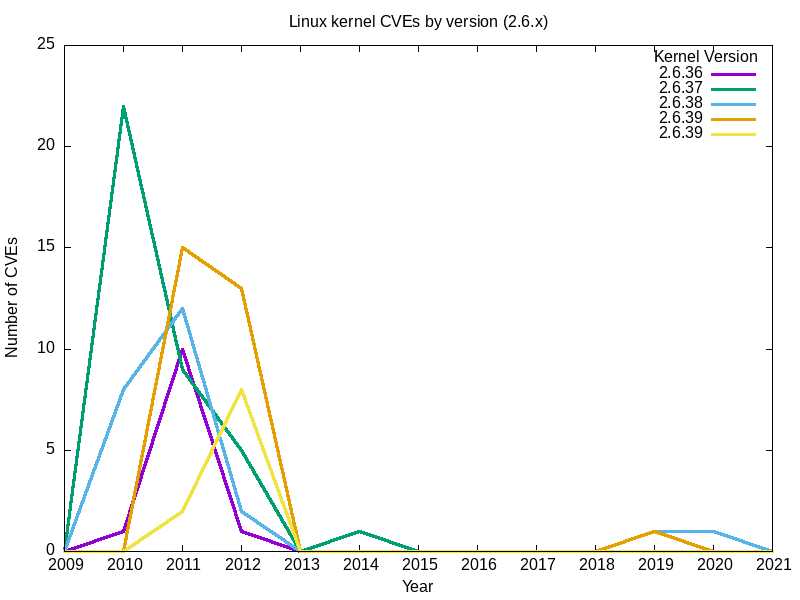
Je vais commencer par examiner les cinq dernières versions (2.6.35 à 2.6.39) de la fameuse branche 2.6.x du noyau Linux.
Requête 2 - CVEs du noyau Linux par année et version du noyau
- Exécutez ceci pour créer un fichier de requête :
| export QRY=“3-linux-kernel-cves-by-year-and-version” cat<<EOF>qry/${QRY}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Fais ça.
| export VERS_MAJOR=2.6 VERS_MINOR_START=35 VERS_MINOR_STOP=39 YEAR_START=2009 YEAR_STOP=$(date +%Y) VERSIONS=() COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” export OUT=“${QRY}_${VERS_MAJOR}.x” for VERS_MINOR in $(seq ${VERS_MINOR_START} ${VERS_MINOR_STOP}); do VERSIONS+=(${VERS_MAJOR}.${VERS_MINOR}); done (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
- Le résultat :
| 2.6.35 2.6.36 2.6.37 2.6.38 2.6.39 2009 0 0 0 0 0 2010 1 22 8 0 0 2011 10 9 12 15 2 2012 1 5 2 13 8 2013 0 0 0 0 0 2014 1 1 0 0 0 2015 0 0 0 0 0 2016 0 0 0 0 0 2017 0 0 0 0 0 2018 0 0 0 0 0 2019 0 0 1 1 0 2020 0 0 1 0 0 2021 0 0 0 0 0 |
- Exécutez ceci pour créer le script gnuplot :
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version (`echo ${VERS_MAJOR}`.x)” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/`echo ${OUT}`.tsv” using 1:c with lines lw 3 EOF |
- Exécutez gnuplot pour créer le fichier image.
| gnuplot -c bin/${OUT}.gnuplot |
- Voici le mien.
Script pour les CVEs du noyau Linux 3.x, 4.x, 5.x par année et version
Voici un script qui combine les trois dernières commandes en un seul bloc, et utilise des variables d'environnement pour interroger les cinq dernières versions des autres branches majeures du noyau Linux.
Enregistrez le code dans un fichier, rendez-le exécutable puis exécutez-le. Et attendez.
| #!/bin/bash # Script to chart Linux kernel CVEs for kernel versions # 3.x, 4.x, 5.x. # You must have loaded a CouchDB database with CVE # data as described here: # https://blog.kernelcare.com/linux-kernel-cve-data-analysis-part-1-importing-into-couchdb # Parallel arrays for Linux kernel versions: # 3.0-3.19 (2011-DATE) # 4.0-4.20 (2015-DATE) # 5.0-5.12 (2019-DATE) VERS_MAJOR=(3 4 5) VERS_MINOR_START=(0 0 0) VERS_MINOR_STOP=(19 20 12) YEAR_START=(2011 2015 2019) YEAR_STOP=$(date +%Y) # admin/password are CouchDB admin login credentials COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” ## # Construct version string from args # and set VERSIONS. # Args: # 1: Major version number # 2: Minor version start number # 3: Minor version stop number build_versions() { VERSIONS=() for VERS_MINOR in $(seq ${2} ${3}); do VERSIONS+=(${1}.${VERS_MINOR}) done } ## # Write a query file to qry subdir # Args: # 1: Name of query file without extension write_query() { cat<<EOF>qry/${1}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF } ## # Run the query # run_query() { (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START[$i]} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv } # Run a gnuplot script with values supplied # by: # 1: Base of filename # 2: Major version number # 3: As per 1 run_gnuplot() { printf ‘ reset set terminal png size 800,600 set output “img/%s.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version %s.x” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/%s.tsv” using 1:c with lines lw 3 ‘ $1 $2 $1 | gnuplot – } main() { write_query ${QRY} for i in 0 1 2; do build_versions ${VERS_MAJOR[$i]} ${VERS_MINOR_START[$i]} ${VERS_MINOR_STOP[$i]} OUT=“${QRY}_${VERS_MAJOR[$i]}.x” run_query run_gnuplot $OUT ${VERS_MAJOR[$i]} done } main |
Voici les graphiques qui en résultent.
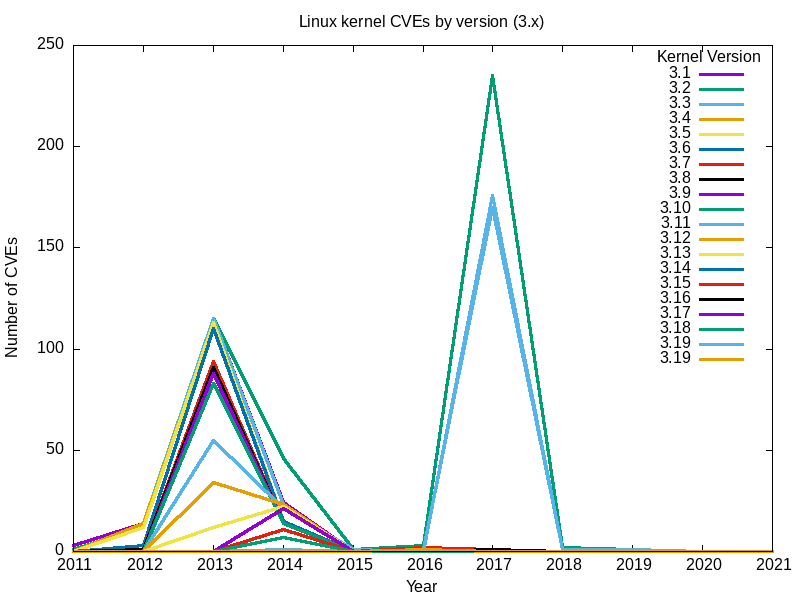
Oui, le gros pic de 2017 était principalement dû aux vulnérabilités trouvées dans 3.18.
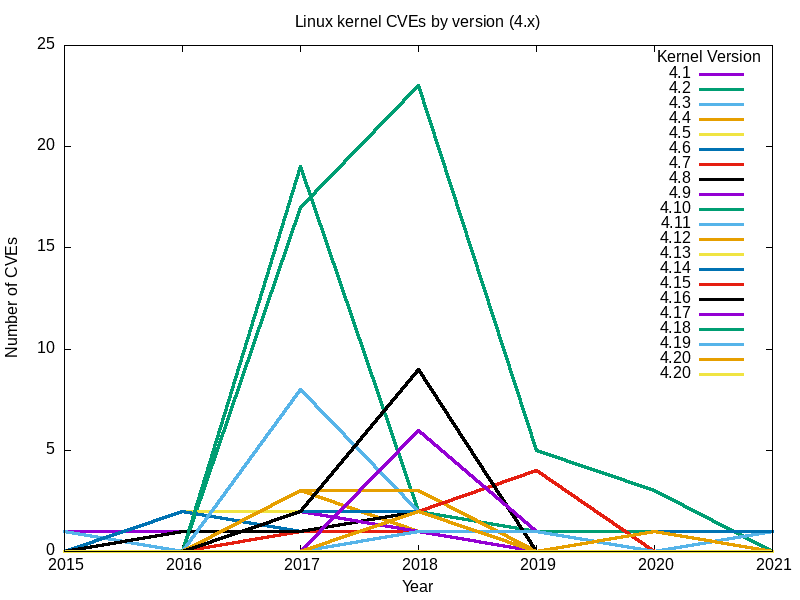
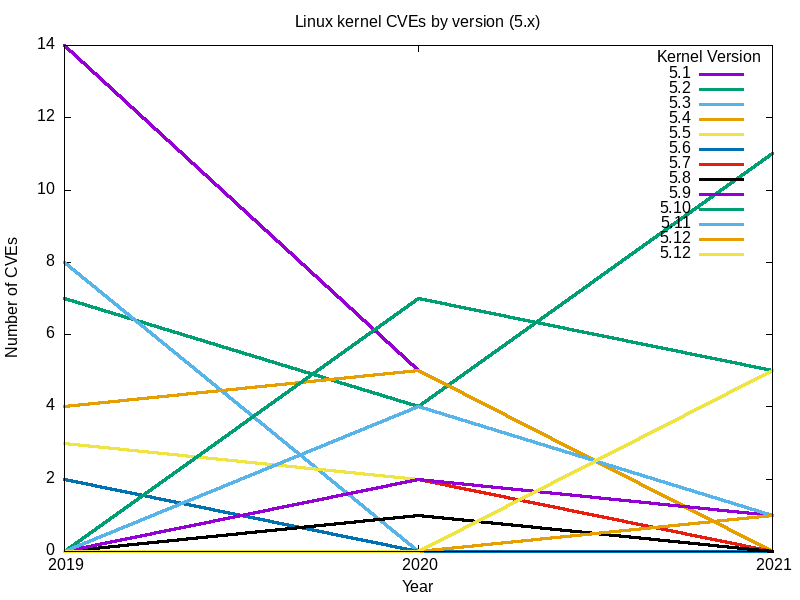
Conclusions
-
L'ensemble des graphiques pour toutes les principales branches du noyau Linux semble répondre à ma question initiale : le noyau Linux le plus sûr (celui qui présente le moins de vulnérabilités) est le dernier[Note de l'éditeur : au moment de la rédaction de cet article], la version 5.12.
-
L'effet de nombreuses vulnérabilités s'étend au-delà des branches et des dates de "fin de vie". Par exemple, pour 2.6, la dernière version, 2.6.39, date de mai 2011. Elle a été désignée comme "fin de vie" à la version 2.6.39.4 en août de la même année. Néanmoins, les rapports de vulnérabilités n'ont pas cessé, et ont augmenté depuis 2016.
-
Comparer les vulnérabilités branche par branche n'est pas la meilleure méthode. Les branches sont continues, la version finale d'une branche formant la base de la suivante. Par exemple, la version 5.0 est une continuation de la branche 4.x, la 4.0 une continuation de la 3.19, et la version finale 2.6.39 de la longue branche 2.6 qui s'est poursuivie dans la 3.0. La façon dont les bases de code sont ramifiées de cette manière signifie que chaque branche suivante aura progressivement moins de bogues.


