 Documentation
Documentation Login
LoginLinux Kernel CVE Data Analysis (updated)

December 13, 2021 - TuxCare PR Team
If you’re interested in Linux security, kernel vulnerabilities or simply have some spare time to run some tests, this article is for you. In it, we provide an updated version of a methodology you can use to extract data from CVE repositories and create your own statistical analysis. Find out which kernel versions have the most identified vulnerabilities.
|
Editor note: This article is an updated version of a series of articles published in the old KernelCare blog. In the time since their publication, the data format on the CVE repositories changed, so the original instructions no longer worked. Rather than updating old articles that would get no visibility, we are republishing the whole content with working step-by-step instructions. We realize that the results are somewhat skewed due to some kernel versions having wider spread adoption than others, and thus are tested more extensively, and CVE’s not being the best way to assert the (in)security level of any given kernel version. However, it is still an interesting exercise and, if nothing else, it will let you exercise multiple tools you might otherwise never use. You now have a way to check claims of “so many vulnerabilities for this or that kernel” for yourself, and with this foundational work you could, with some changes, track other projects’ vulnerabilities instead of just the kernel. A “thank you” to Paul Jacobs, who submitted the updated version of his original articles. |
Content
Part 1 – Setup and data acquisition
Part 3 – Advanced queries and graphs
Updated for 2021. Changes:
-
- Mango query selector syntax updated for CVE 1.1 specification.
- Uses CouchDB Docker container.
Part 1
Linux kernel developers tell us that the ‘best’ Linux kernel to use is the one that comes with whatever distribution we’re using. Or the latest stable version. Or the most recent long-term support (LTS) version. Or whatever one we want, so long as it’s maintained.
Choice is great, but I’d rather have a single answer; I just want the best. The trouble is, for some people, best means fastest. For others, the best is the one with the latest features, or a specific feature. For me, the best Linux kernel is the safest one.
Which is the ‘safest’ Linux kernel?
A crude way to consider the safety of a piece of software is to see how many security issues appear in a specific version of it. (I know it’s a shaky premise, but let’s run with it, if only as a way to learn more about CVEs and how to interpret them.) Applying this tactic to the Linux kernel means examining vulnerability reports.
That’s what I’ll be doing in this series of three articles. I’ll be analyzing Linux kernel CVEs (reported vulnerabilities) to see if there are any trends that can help answer the question, Which is the best (i.e. safest) Linux kernel to use.
But wait–hasn’t this been done already?
Kind of.
-
CVE Details: A CVE search engine. You can find CVEs by severity, product, vendor, etc.
-
Linux Kernel CVEs: Also a CVE search engine, listing CVE IDs for specific Linux kernel versions.
-
Alexander Leonov: Nice article on the anatomy of a CVE data file, but with a focus on CPE data.
-
Tenable.sc: Commercial product with a CVE analysis dashboard.
So, why do this?
Because either those resources and projects don’t answer my question, or they cost money.
And besides, I want to learn what a CVE is, what they can tell me about the differences (if any) between Linux kernel versions, and what the limitations of this approach is.
The process and tools
It’s pretty simple; get the data, analyze it, chart the results.
The tools are free and run on many platforms. I’ll be working on Debian Linux, and will assume you’re not fazed by the sight of a naked terminal.
Just so you know what you’re in for, here are the key steps.
-
Use Docker to run the latest version of Apache CouchDB. (This will be a single-node set-up—I want to explore the data, not get bogged down with administration.)
-
Download NVD data (as JSON files) and import all CVE records, not just those for the Linux kernel. (This way it’s easier to select relevant data at query time than it is to parse and extract records from the JSON files.)
-
Use Mango to query the data.
First, here’s a bit of background on what a CVE is, and what a CVE record contains.
What is a CVE?
CVE stands for Common Vulnerability and Exposures.
For our purposes, a CVE is a code that identifies a software vulnerability. It’s in the form CVE-YYYY-N, where YYYY is the year the ID was assigned or made public, and N is a sequence number of arbitrary length. An organization called Mitre coordinates the CVE list.
Clearly, a CVE isn’t defined by its ID, but by its details. A number or organizations look after these details, but the one I’ll use is the most well-known, the National Vulnerability Database (NVD), managed by the National Institute of Standards and Technology (NIST). Anyone can download their CVE data for free.
NIST have some simple bar charts that show how the severity of vulnerabilities varies by year. These are charts of all software CVEs (not just Linux ones), from 2001 to the present year. I want something similar, but only for Linux vulnerabilities, and broken down by kernel version, too.
What’s in a CVE?
Before I load and query the JSON-format vulnerability files, let me show you what’s in them. (There is a file specification schema, but it has a lot of detail we don’t need to know about.) Each NVD CVE file contains a year’s worth of CVEs (January 1 to December 31). Here’s the basic structure of a CVE entry.
-
The first JSON section is a header, comprising the data format, version, number of records, and a timestamp.
-
The rest is one large array,
CVE_Itemswith these sub-elements:cveproblemtypereferencesdescriptionconfigurationsimpact- and two date fields,
publishedDateandlastModifiedDate.
The one of interest is
configurations. It contains:nodes, an array of:children, an array of:cpe_match, comprising:vulnerablecpe23Uri: A Common Platform Enumeration string.cpe_name
It is the
cpe23Uriandimpactparts that I’ll eventually query on.-
The impact block defines the severity of a vulnerability as a number and a name using the Common Vulnerability Scoring System (CVSS). (There are two versions, 2.0 and 3.0. They differ slightly as shown below.)
-
The number is the Base Score Range (
baseScore), a decimal value from 0.0 to 10.0. -
The name (
severity) is one of LOW, MEDIUM or HIGH (for CVSS V2.0; NONE and CRITICAL are added in v3.0).
-
CVSS v2.0 vs v3.0
The two versions differ in how they map the base score to severity. (The table below comes from the NVD CVSS page.)
| CVSS v2.0 Ratings | CVSS v3.0 Ratings | ||
|---|---|---|---|
| Severity | Base Score Range | Severity | Base Score Range |
| None | 0.0 | ||
| Low | 0.0-3.9 | Low | 0.1-3.9 |
| Medium | 4.0-6.9 | Medium | 4.0-6.9 |
| High | 7.0-10.0 | High | 7.0-8.9 |
| Critical | 9.0-10.0 | ||
Now I’ll set up CouchDB, load the data, and query it with Mango.
Run CouchDB via Docker
-
Get Docker for your platform.
-
Copy and paste these commands into a terminal and run them. (From now on, I’ll assume you can recognize a command when you see one and know what to do with it.)
sudo docker run -d
-p 5984:5984
-e COUCHDB_USER=admin
-e COUCHDB_PASSWORD=password
–name couchdb couchdb- I’ll use
passwordhere. Choose your own but watch where it’s used from here on. - If you prefer to install CouchDB natively (as a regular application installation, rather than inside a container), see docs.couchdb.org.
- I’ll use
-
Open a web browser and go to http://localhost:5984/_utils
-
Log in with the credentials used in the Docker command (the values for
COUCHDB_USERandCOUCHDB_PASSWORD). -
In the Databases pane, select Create Database.
-
In Database name, enter
nvd(or your own choice of database name). -
For Partitioning, select Non-partitioned.
- Click Create.
Import CVE Data into CouchDB
- Check curl and jq are on your system (or install them if not).
| curl –version || sudo apt install -y curl jq –version || sudo apt install -y jq |
- Install Node.js and the couchimport tool.
| sudo apt-get install -y npm npm install -g couchimport |
- Download CVE JSON data files.
| VERS=“1.1” R=“https://nvd.nist.gov/feeds/json/cve/${VERS}/” for YEAR in $(seq 2009 $(date +%Y)) do FILE=$(printf “nvdcve-${VERS}-%s.json.gz” $YEAR) URL=“${R}${FILE}“ echo “Downloading ${URL} to ${FILE}“ curl ${URL} –output ${FILE} –progress-bar –retry 10 done |
-
- Adjust the year range to suit your interests. NVD have data from 2002.
- The version changes from time to time. Check https://nvd.nist.gov/vuln/data-feeds and set VERS accordingly, but check for data file format changes.
- Decompress the files.
| gunzip *.gz |
- Import CVE data into the CouchDB database.
| export COUCH_URL=“http://admin:password@localhost:5984” COUCH_DATABASE=“nvd” COUCH_FILETYPE=“json” COUCH_BUFFER_SIZE=100 for f in $(ls -1 nvdcve*.json); do echo “Importing ${f}“ cat ${f} | couchimport –jsonpath “CVE_Items.*” done |
-
- Change COUCH_DATABASE if you created it with a different name.
- Use the –preview true option to do a dry run.
- If any fail, reduce the size of COUCH_BUFFER_SIZE. The default is 500 but (for me) importing 2020’s data fails unless the buffer size is lowered.
- Read more about couchimport.
- Check the number of records in the database is the same as in the files. (The counts from these two commands should be the same.)
| grep CVE_data_numberOfCVEs nvdcve*.json | cut -d‘:’ -f3 | tr –cd ‘[:digit:][:cntrl:]’ | awk ‘{s+=$1} END {print s}’ |
| curl -sX GET ${COUCH_URL}/nvd | jq ‘.doc_count’ |
-
- If the counts differ, check the output from the previous step and look for import failures.
Run a Mango Query in Fauxton
To make this first query easy, I’ll use Fauxton, the CouchDB browser-based UI. But don’t get too comfortable with it, because in Parts 2 and 3 I’ll work solely on the command line.
- In a browser, go to: http://localhost:5984/_utils/#database/nvd/_find
Fauxton will log you out after a period of inactivity. If this happens, log out and back in again, navigate to Databases then select the nvd database (if that’s the name you used), then Run A Query with Mango. - Delete the contents of the Mango Query pane, then copy and paste this query text into it:
| { “selector”: { “configurations.nodes”: { “$elemMatch”: { “operator”: “OR”, “cpe_match”: { “$elemMatch”: { “cpe23Uri”: { “$regex”: “linux_kernel” } } } } }, “publishedDate”: { “$gte”: “2021-01-01”, “$lte”: “2021-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } |
- Set Documents per page to its highest value.
- Click Run Query.
The result is a list of the CVE IDs of Linux kernel vulnerabilities for all severities and kernel versions, assigned or published in 2021.
Homework
- Copy and paste the cve.CVE_data_meta.ID into the NVD search page to see the details of any CVE.
- Experiment with different date ranges. For example, to start at January 2019, replace the publishedDate element with:
“publishedDate”: {
“$gte“: “2019-01-01”,
“$lte“: “2019-12-31”
}
Congratulations. You are now the proud owner of a CouchDB database bulging with over a decade’s worth (or whatever you chose) of CVEs. Remember, the database contains data for all software from all vendors.
Next, I’ll add selectors for severity and kernel version, run the queries and chart the results.
Part 2
Preliminaries
Create some directories to keep track of everything.
| mkdir bin qry img out |
- I’ll use them like this:
- bin: scripts;
- qry: Mango query files;
- img: images of charts;
- out: output from queries.
Install Gnuplot.
| sudo apt install -y gnuplot |
Next, I’ll look at how the number of Linux kernel vulnerabilities varies year-on-year. To do that, I’ll add parameters using printf tokens in the Mango queries, with values substituted at run time. (Later, I’ll add parameters for kernel version, too.) To keep things quick and simple, I’ll use the CouchDB POST API to submit queries on the command line.
Query 1a — Linux kernel CVEs by year
Run this to create a Mango query file:
| cat<<EOF>qry/1-linux-kernel-cves-by-year.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Run this.
| for YEAR in $(seq 2009 $(date +%Y)); do echo -en “$YEARt” printf “$(cat qry/1-linux-kernel-cves-by-year.json)“ $YEAR $YEAR | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find –header “Content-Type:application/json” | jq ‘.docs | length’ done | tee out/1-linux-kernel-cves-by-year.tsv |
-
- This runs the query in a loop for every year in the range (line 1), and prints the results both to the console and to out/1-linux-kernel-cves-by-year.tsv (which I’ll use for graphing).
- Change the year range to suit your interests or to match whatever you imported in Part 1.
- If you don’t get any results, check the query file (qry/1-linux-kernel-cves-by-year.json) and your CouchDB credentials (admin/password).
Here’s the output I get.
2009 101
2010 116
2011 81
2012 114
2013 190
2014 137
2015 79
2016 218
2017 453
2018 184
2019 287
2020 125
2021 127
- This is the number of Linux kernel vulnerabilities for each year.
- Some of you numbers may be higher, as vulnerabilities can be retrospectively recorded.
Run this to create a gnuplot script in bin/1-linux-kernel-cves-by-year.gnuplot:
| cat<<EOF>bin/1-linux-kernel-cves-by-year.gnuplot reset set terminal png size 800,600 set output ‘img/1-linux-kernel-cves-by-year.png’ set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right set title ‘Linux Kernel CVEs by Year’ set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [2008.5:*] [] ‘out/1-linux-kernel-cves-by-year.tsv’ w boxes t ‘All severities’, ‘out/1-linux-kernel-cves-by-year.tsv’ u 1:($2+15):2 w labels t ” EOF |
- Run this to create an image file in img/1-linux-kernel-cves-by-year.png:
| gnuplot -c bin/1-linux-kernel-cves-by-year.gnuplot |
- Open img/1-linux-kernel-cves-by-year.png in your favourite image viewer. Here’s mine.
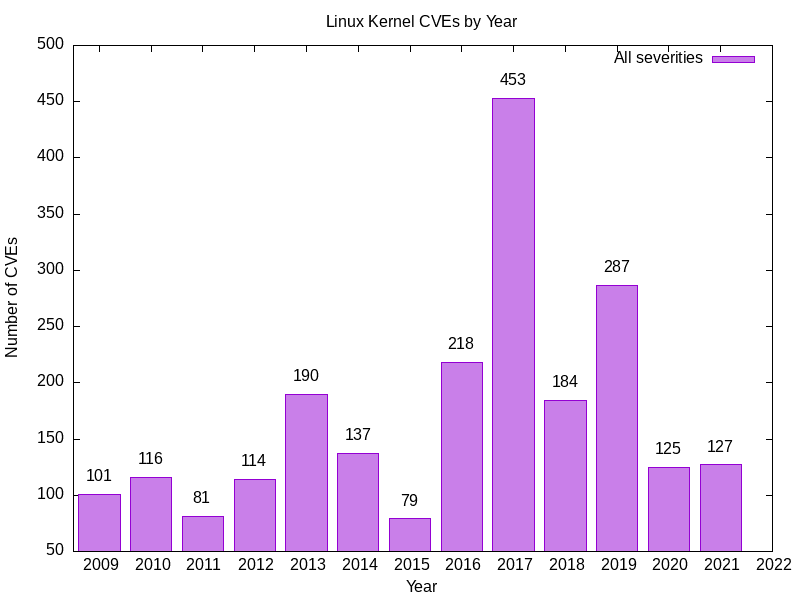
Commentary
That’s a lot of Linux kernel vulnerabilities. 2017 was a spectacularly good/bad year for Linux kernel vulnerabilities.
I was concerned when I saw this, so I cross-checked against other sources, CVEDetails among them. The numbers tally pretty well.
Year Mine CVEDetails
2009 101 104
2010 116 118
2011 81 81
2012 114 114
2013 190 186
2014 137 128
2015 79 79
2016 218 215
2017 453 449
2018 184 178
2019 287 289
2020 125 126
2021 127 130
Any differences can be explained by the observations of CVE Details:
“…CVE data have inconsistencies which affect [the] accuracy of data displayed … For example vulnerabilities related to Oracle Database 10g might have been defined for products ‘Oracle Database’, ‘Oracle Database10g’, ‘Database10g’, ‘Oracle 10g’ and similar.”
In other words, the NVD CVE data is not completely accurate. (More on this later.)
This chart shows the totals CVE counts aggregated across all CVE severities. To break the results down by severity, I will add a selector to the Mango query.
Query 1b – Linux kernel CVEs by year and severity
- Run this to create qry/cve-1b.json (a copy of Query 1a with an added severity parameter):
| cat<<EOF>qry/2-linux-kernel-cves-by-year-and-severity.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel” } } } } }, “impact.baseMetricV2.severity”: “%s”, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Run this.
| export OUT=“2-linux-kernel-cves-by-year-and-severity” SEVS=(LOW MEDIUM HIGH) (IFS=$‘t’; echo -e “YEARt${SEVS[*]}“ | tee out/${OUT}.tsv); for YEAR in $(seq 2009 $(date +%Y)); do RES=() echo -en “$YEARt” for SEV in ${SEVS[*]}; do RES+=($(printf “$(cat qry/${OUT}.json)“ ${SEV} ${YEAR} ${YEAR} | curl -sX POST -d @- http://admin:password@localhost:5984/nvd/_find –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
Here’s my output.
YEAR LOW MEDIUM HIGH
2009 11 51 39
2010 37 47 32
2011 19 41 21
2012 24 66 24
2013 46 126 18
2014 20 87 30
2015 17 44 18
2016 25 114 79
2017 73 91 289
2018 36 93 55
2019 47 151 89
2020 38 64 23
2021 44 59 24
- Run this to create a gnuplot script in bin/cve-1b.gnuplot:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set style data histograms set style histogram rowstacked set style fill solid 0.5 set boxwidth 0.8 relative set xtics 1 set key top right title “Severity” set title “Linux kernel CVEs” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot “out/`echo ${OUT}`.tsv” u ($2):xtic(1) t col, ” u ($3):xtic(1) t col, ” u ($4):xtic(1) t col, ” u ($0-1):($2+10):(sprintf(“%d”,$2)) with labels t ”, ” u ($0-1):($2+$3+10):(sprintf(“%d”,$3)) with labels t ”, ” u ($0-1):($2+$3+$4+10):(sprintf(“%d”,$4)) with labels t ” EOF |
- Run this to create an image file in img/cve-1b.png.
| gnuplot -c bin/${OUT}.gnuplot |
Here’s mine.
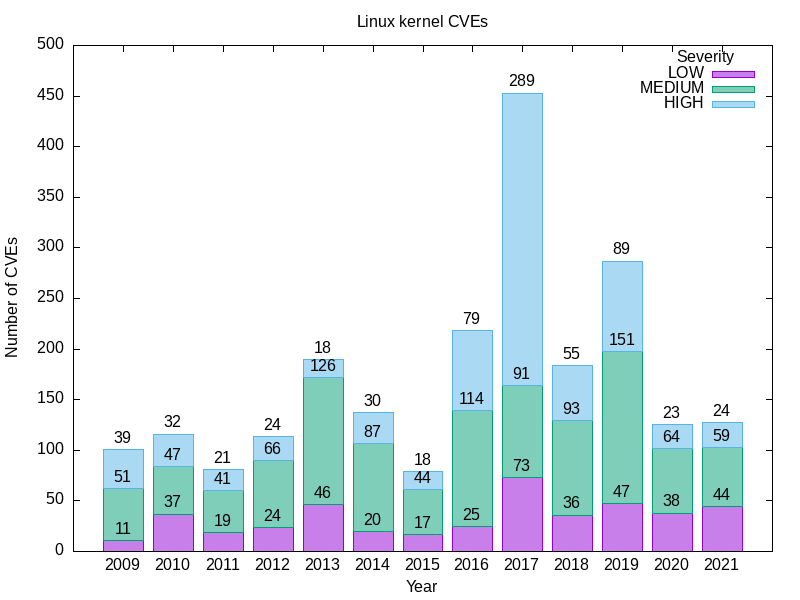
Notes on severity
-
- Query 1b uses CVSS version 2 rather than the more recent version 3. There’s a reason for this. CVSS version 3 was introduced in December 2015; CVEs before that date can only be selected using the version 2 CVSS scheme.
- CVSS versions 2 and 3 both have numerical and textual representations for severity. The numeric is more precise, while the textual is coarser, but easier to relate to. For simplicity, I’m using the textual scheme. I’ll change to the numeric scheme later, for accuracy.
Query 1b is a sharper picture than Query 1a but no less shocking. For instance, compare the relative proportions of HIGH severity Linux kernel vulnerabilities to those before and after 2016.
It could be that many of these vulnerabilities are concentrated in a few kernel versions. I won’t know until I modify the query to select on version as well as year and severity. That’s coming next.
Part 3
Here, in Part 3, I develop that core Mango query to look at how the number of Linux kernel vulnerabilities varies by kernel version.
Because there are so many versions, the queries and commands start to get more complicated, and take longer to complete. So, for now, I will only vary the year and kernel version. Severity remains a parameter, but I will query results for all severities.
I’ll start by looking at the last five releases (2.6.35 to 2.6.39) of the famously long-running 2.6.x Linux kernel branch.
Query 2 — Linux kernel CVEs by year and kernel version
- Run this to create a query file:
| export QRY=“3-linux-kernel-cves-by-year-and-version” cat<<EOF>qry/${QRY}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF |
- Run this.
| export VERS_MAJOR=2.6 VERS_MINOR_START=35 VERS_MINOR_STOP=39 YEAR_START=2009 YEAR_STOP=$(date +%Y) VERSIONS=() COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” export OUT=“${QRY}_${VERS_MAJOR}.x” for VERS_MINOR in $(seq ${VERS_MINOR_START} ${VERS_MINOR_STOP}); do VERSIONS+=(${VERS_MAJOR}.${VERS_MINOR}); done (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv |
- The output:
| 2.6.35 2.6.36 2.6.37 2.6.38 2.6.39 2009 0 0 0 0 0 2010 1 22 8 0 0 2011 10 9 12 15 2 2012 1 5 2 13 8 2013 0 0 0 0 0 2014 1 1 0 0 0 2015 0 0 0 0 0 2016 0 0 0 0 0 2017 0 0 0 0 0 2018 0 0 0 0 0 2019 0 0 1 1 0 2020 0 0 1 0 0 2021 0 0 0 0 0 |
- Run this to create the gnuplot script:
| cat<<EOF>bin/${OUT}.gnuplot reset set terminal png size 800,600 set output “img/`echo ${OUT}`.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version (`echo ${VERS_MAJOR}`.x)” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/`echo ${OUT}`.tsv” using 1:c with lines lw 3 EOF |
- Run gnuplot to create the image file.
| gnuplot -c bin/${OUT}.gnuplot |
- Here’s mine.
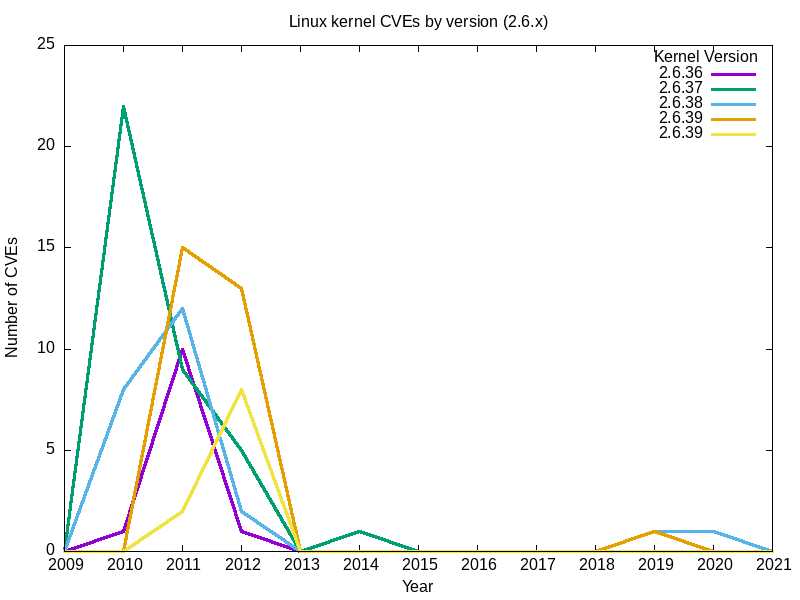
Script for Linux kernel 3.x, 4.x, 5.x CVEs by year and version
Here is a script that combines the last three commands into a single block, and uses environment variables to query the last five releases of the other major Linux kernel branches.
Save the code to a file, make it executable then run it. And wait.
| #!/bin/bash # Script to chart Linux kernel CVEs for kernel versions # 3.x, 4.x, 5.x. # You must have loaded a CouchDB database with CVE # data as described here: # https://blog.kernelcare.com/linux-kernel-cve-data-analysis-part-1-importing-into-couchdb # Parallel arrays for Linux kernel versions: # 3.0-3.19 (2011-DATE) # 4.0-4.20 (2015-DATE) # 5.0-5.12 (2019-DATE) VERS_MAJOR=(3 4 5) VERS_MINOR_START=(0 0 0) VERS_MINOR_STOP=(19 20 12) YEAR_START=(2011 2015 2019) YEAR_STOP=$(date +%Y) # admin/password are CouchDB admin login credentials COUCHDB_URL=“http://admin:password@localhost:5984/nvd/_find” QRY=“3-linux-kernel-cves-by-year-and-version” ## # Construct version string from args # and set VERSIONS. # Args: # 1: Major version number # 2: Minor version start number # 3: Minor version stop number build_versions() { VERSIONS=() for VERS_MINOR in $(seq ${2} ${3}); do VERSIONS+=(${1}.${VERS_MINOR}) done } ## # Write a query file to qry subdir # Args: # 1: Name of query file without extension write_query() { cat<<EOF>qry/${1}.json { “selector”: { “configurations.nodes”: { “$elemMatch“: { “operator”: “OR”, “cpe_match”: { “$elemMatch“: { “cpe23Uri”: { “$regex“: “linux_kernel:%s” } } } } }, “publishedDate”: { “$gte“: “%s-01-01”, “$lte“: “%s-12-31” } }, “fields”: [ “cve.CVE_data_meta.ID” ], “limit”: 999999 } EOF } ## # Run the query # run_query() { (IFS=$‘t’; echo -e “t${VERSIONS[*]}“ | tee out/${OUT}.tsv); for Y in $(seq ${YEAR_START[$i]} ${YEAR_STOP}); do RES=() echo -en “${Y}t” for V in ${VERSIONS[*]}; do RES+=($(printf “$(cat qry/${QRY}.json)“ ${V} ${Y} ${Y} | curl -sX POST -d @- ${COUCHDB_URL} –header “Content-Type:application/json” | jq ‘.docs | length’)) done (IFS=$‘t’; echo “${RES[*]}“) done | tee -a out/${OUT}.tsv } # Run a gnuplot script with values supplied # by: # 1: Base of filename # 2: Major version number # 3: As per 1 run_gnuplot() { printf ‘ reset set terminal png size 800,600 set output “img/%s.png” set xtics 1 set key top right autotitle columnheader title “Kernel Version” set title “Linux kernel CVEs by version %s.x” set xlabel “Year” set ylabel “Number of CVEs” set autoscale y plot [] [] for [c=2:*] “out/%s.tsv” using 1:c with lines lw 3 ‘ $1 $2 $1 | gnuplot – } main() { write_query ${QRY} for i in 0 1 2; do build_versions ${VERS_MAJOR[$i]} ${VERS_MINOR_START[$i]} ${VERS_MINOR_STOP[$i]} OUT=“${QRY}_${VERS_MAJOR[$i]}.x” run_query run_gnuplot $OUT ${VERS_MAJOR[$i]} done } main |
Here are the resulting charts.
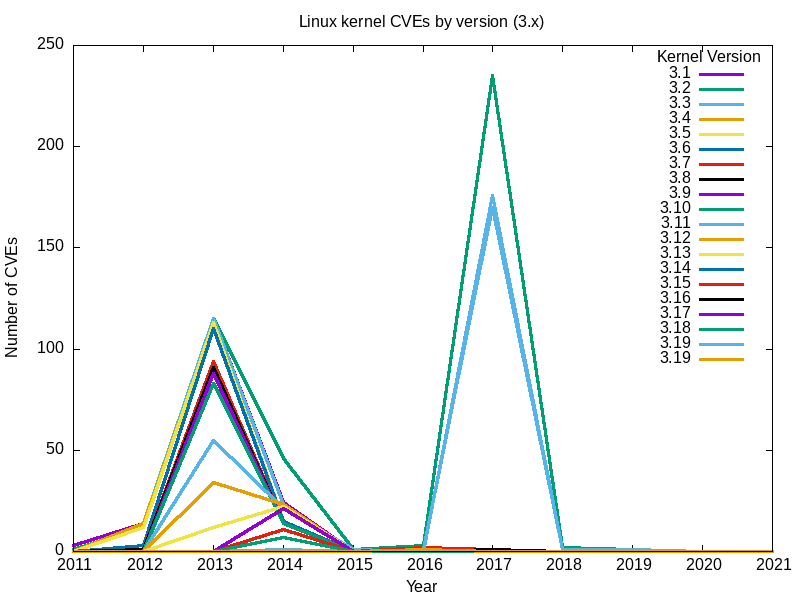
Yes, the big spike in 2017 was mainly due to vulnerabilities found in 3.18.
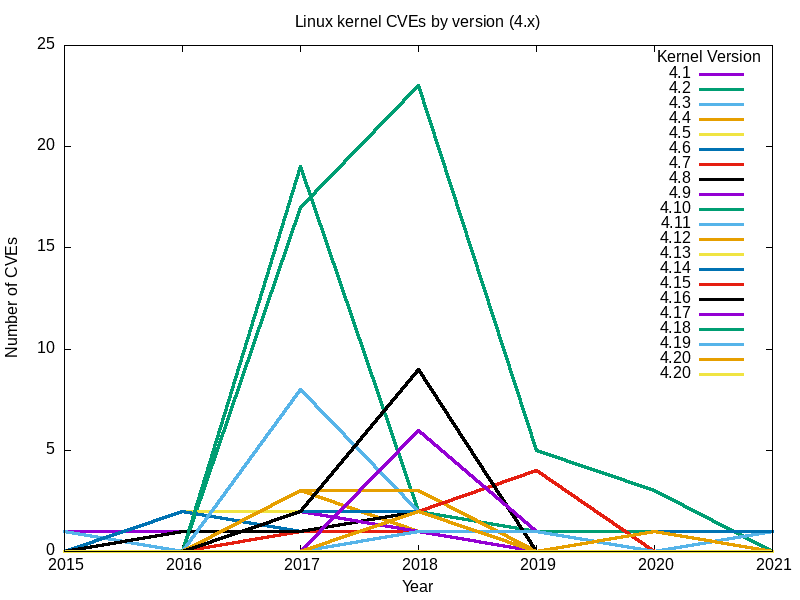
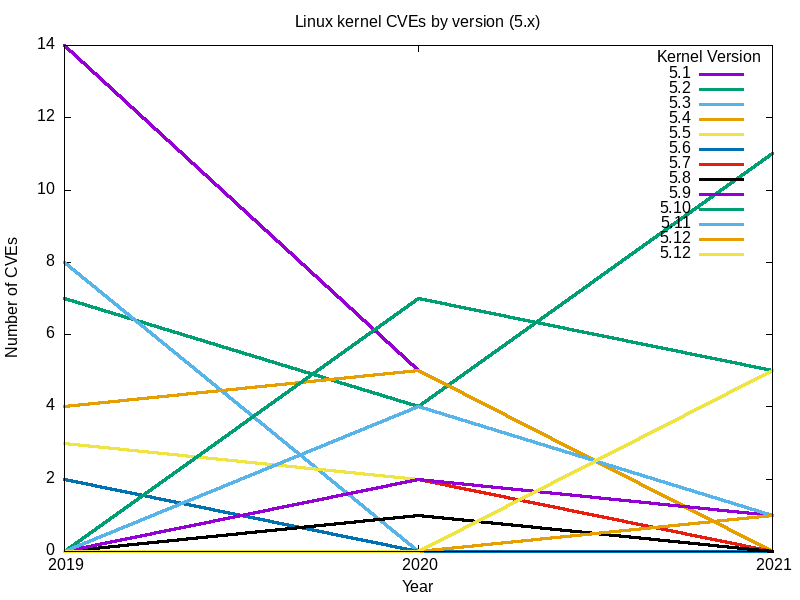
Conclusions
-
Taken together, the complete set of graphs for all major Linux kernel branches seems to answer my original question: the safest Linux kernel (the one with the least vulnerabilities) is the latest [Editor note: at the time this article was written], version 5.12.
-
The effect of many vulnerabilities extends beyond branches and ‘End of Life’ dates. For example, for 2.6, the last release, 2.6.39, was in May 2011. It was designated ‘end of life’ at version 2.6.39.4 in August the same year. Nevertheless, reports of vulnerabilities haven’t stopped, and have increased since 2016.
-
Comparing vulnerabilities branch-by-branch is not the best way. Branches are continuous, with the final release of one branch forming the basis of the next. For example, 5.0 is a continuation of the 4.x branch, 4.0 a continuation of 3.19, and the final 2.6.39 release of the long-running 2.6 branch continued in 3.0. The way code bases are branched like this means that each subsequent branch will have progressively fewer bugs.


