 Documentation
Documentation Login
LoginTo Reboot or Not to Reboot? That is the Question for Many Sysadmins

November 12, 2020 - TuxCare PR Team
 A server reboot cycle is a generic name given to the process of rebooting a fleet of servers in an organization. This can be due to several factors, but it is often because patches and updates require a reboot – they either target a critical component of the operating system or some shared library being used by several components or programs. The number of servers that will be rebooted directly impacts the operation’s duration and the associated risk. The more servers that need to be updated, the harder is the planning and execution process.
A server reboot cycle is a generic name given to the process of rebooting a fleet of servers in an organization. This can be due to several factors, but it is often because patches and updates require a reboot – they either target a critical component of the operating system or some shared library being used by several components or programs. The number of servers that will be rebooted directly impacts the operation’s duration and the associated risk. The more servers that need to be updated, the harder is the planning and execution process.
To provide businesses with a rebootless way of handling such security updates, live patching was created. The method’s main advantage is that it doesn’t require a reboot, reducing typical patching cycle tasks by 60 percent. Still, many companies are working with reboot cycles as opposed to the live patching method. Is there a reason for this? Here, we will examine the problem.
Contents:
- Risk to Updating. Risk to Not Updating:
Equifax: A Cautionary Tale
Does Live Patching Slow Down Systems? - Rebooting vs. Rebootless
- The Winner: Pathing Without Rebooting
- Conclusion

Risks to Updating. Risks to Not Updating.
When you update your Kernel, there are always new potential risks involved in it, which is one reason why some may not have embraced live patching updates yet. If their servers are already stable, have decent speed, and do not need new functionality, they may not want to risk the server downtime required to apply the patches. While these might seem like perfectly reasonable reasons to not apply a patch, there is one reason why you absolutely should, even if you have one or more of these reasons: security.
As soon as a new Kernel patch is announced, hackers begin looking for ways to exploit the vulnerability that is being patched. If you never update that patch, you will always leave a back door open for hackers to get into your systems. This is precisely why we still find hackers exploiting the HeartBleed vulnerability today, even though the patch to fix that was released in 2014. It is one of the most devastating vulnerabilities, yet some systems have still not applied the patch to take this backdoor away from hackers.

Equifax: A Cautionary Tale
According to a Ponemon survey, 60 percent of respondents say one or more of the breaches their organizations experienced last year were from a known vulnerability that has a patch to fix it; yet they never applied the patch. Approximately 88 percent said that before they can apply a patch, they have to coordinate with other departments in their organization, and that can delay the patching by up to 12 days. The longer the delay, the more time hackers have to find that backdoor into your system.
The Equifax 2017 breach is a prime example of a vulnerability that had a patch that was not applied. Equifax was aware of the Apache Struts (CVE-2017-5638) vulnerability, but they did not patch the system. The CEO of Equifax at the time said they had not found the vulnerability in their scans of the system, so the patch had not been applied like it was supposed to be. Since the patch was not applied, 145.5 million Americans had their information stolen. If they had been using a live patching system, this data breach could have been avoided.

Does Live Patching Slow Down Systems?
Some may choose not to switch to live patching because they believe that live updates will slow down their systems, and even a small slowdown can lead to problems for an organization. There are a number of things that can slow a system down, including vulnerabilities themselves, and using temporary patching instead of persistent.
With temporary patching, your updates are applied to the server, but you still have to reboot it to fully apply the patches. Additionally, the patches still get stacked on top of each other and can begin to slow the system down on their own. With persistent live patching, everything is done without requiring reboots or slowing down the system.

Rebooting vs. Rebootless
To compare live patching and regular patching with reboots, there are several aspects we need to consider since the comparison changes depending on the type of system we are looking at.
Physical Servers: For physical servers, a reboot operation always takes at least a few minutes to happen because of the power-on self-test (POST) operation that is performed to check hardware components. In this case, it is always faster and more efficient to perform live patching because it takes less time, and service availability is higher. This is the typical case where live patching with KernelCare Enterprise is always better in every regard.
Thick Virtualized Servers: For thick virtualized servers, reboot time is less of a factor, but it also involves some downtime when performing regular patching and rebooting. This has a ripple effect on other systems, affects redundancy of the services provided, requires a maintenance window, and has more impact than live patching.
Thin Virtualized Servers: On thin virtualized systems, is where things could be more balanced, because rebooting a container is the same as destroying and recreating it, and that is the optimal use case for containers. However, a container shares the kernel with the host where it is running, so live patching the host’s kernel with KernelCare Enterprise means it automatically patches the containers too. This is better because it eliminates the need to take the container down and recreate it, however fast or slow that may be.
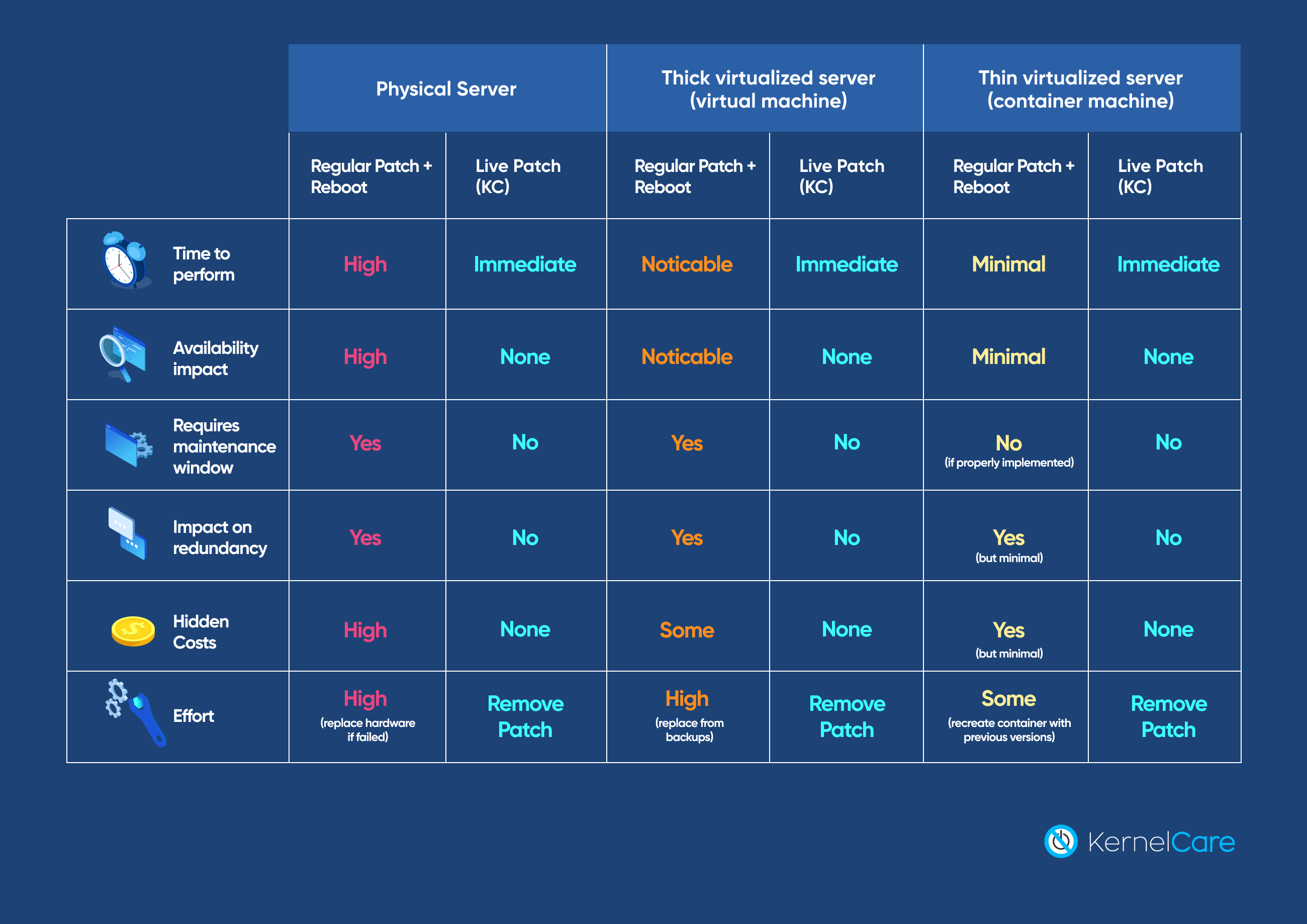
When performing this operation on multiple servers, it has to be done, so that service availability is maintained, and this is easier to do if you have many servers. This means that larger organizations can do it more efficiently than smaller organizations, because they have more redundant servers. Still, even in the best case of having fully containerized services, having live patching on the host servers has less impact than recreating the containers with updated versions.

The Winner: Patching Without Rebooting
As we saw with the Equifax breach and the continued exploitation of the HeartBleed vulnerability six years later, the only way to avoid breaches is to apply patches quickly. However, the downtime required to reboot a system can potentially leave it vulnerable. The only solution is a live patching system that does not require a reboot.
Conclusion
When a system has 1,000 or more servers, it can be challenging to keep them all up to date on your own, especially if you have to coordinate downtime between departments. KernelCare Enterprise offers live patching without a reboot, so you never have any downtime, and you are not leaving your system exposed with unpatched vulnerabilities. Keep Enterprise servers always up-to-date and protected from data breaches with KernelCare Enterprise.
Get a FREE 7-Day Supported Trial of KernelCare


